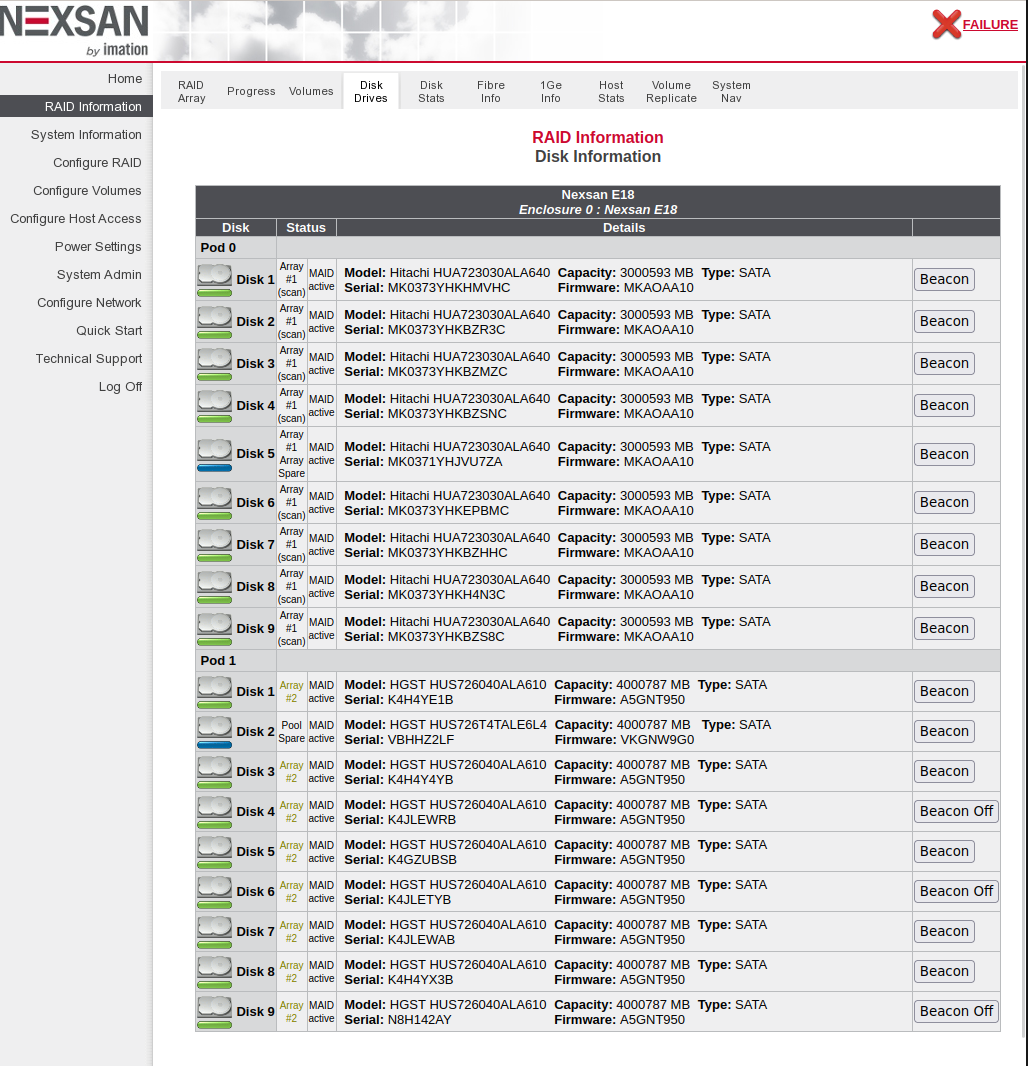
Disk#2 in Pod#1 (for full frames) is now broken.
Because I'm now in the mine, I asked Ikeda-san to check the spare disk exists in the Mozumi building or not.
-----
E18 disk storage is constructed as RAID5 + Hot Spare. Now one HDD is broken and Hot Spare is used. Though it can keep running by the RAID5 parity even if one more disk is broken, it's better to replace the broken disk ASAP. A required spec is 4TB/7200rpm. Now waiting a check of stocks. I have 5400rpm one, but it's probably better not to mix different specs in the RAID system.
I think it's best not to mix HDDs with different rotation speeds. In fact, it's best to use HDDs with the same number of sectors, tracks, and cylinders. If they are different, they will be formatted to match the smaller one in general.
I heard that we purchased spare one from vendor support when a same issue occurred in the past.
Procurement and replacement of disk (should be as hot swap) can be done by DGS.
A reason why I posted it here is E18 is physically mounted from hyades and k1fw0 just mounts it via NFS.
(Area of responsibility and actual connection is twisted in the old iKAGRA system.)
If we need reboot/relaunch DMG's data transfer at hyades-0 caused by working on E18 disk system, let us know.
But I suspect that there maybe no need to relaunch, because RAID will reconstruct with new disk by itself without stopping the operation.
Thank you in advance.
[YamaT-san, Ikeda]
We replaced the drive in Pod#1 Disk#2 of E18 (Fig. 3) with a replacement HDD obtained from Cross Head (Fig. 1) (the drive with the red LED shown in Fig. 2).
After the replacement, the drive entered standby status as a Pool Spare (Fig. 4), and we confirmed that the LED changed to green (Figs. 5 & 6).
Additionally, the log time was set to 2006, so we corrected the system time.
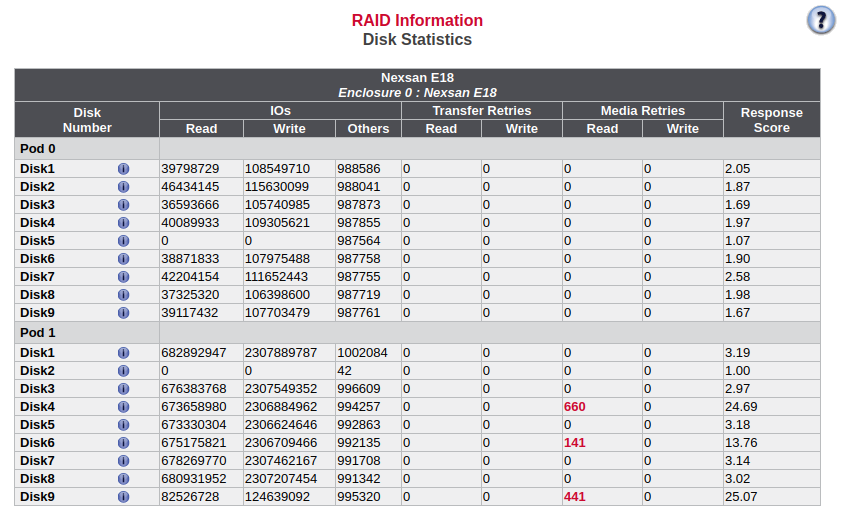
After the replacement, several read errors occurred (Fig. 7), and we are planning to replace it again once additional HDDs arrive.
[Documentation]
T2516683 E18 Maintenance Manual






[YamaT-san, Ikeda]
This is a follow-up to K-Log#33798:
Summary
The remaining three HDDs purchased additionally for E18 have been delivered.
We will replace them one at a time, starting with the one showing the most retries.
Today, we replaced Disk4 Pod1.
Procedure
1. Force failure of Disk4 Pod1. (See Fig-1)
At this point, rebuilding begins on Disk2 Pod1, which was set as a Hot Spare previously.
(Started on 2025-05-29 13:18:27)0004:C0 28-May-2025 at 19:18:27:(I): Rebuild: disk (L3) is rebuilding from stripe 0 on raid set 2
→ The time seems off again.
2. Replace the Disk4 Pod1 HDD with a new one. (See Fig-2)
3. Set the new Disk4 Pod1 HDD as a Hot Spare. (See Fig-3)
After this, we will wait until the rebuild is complete.
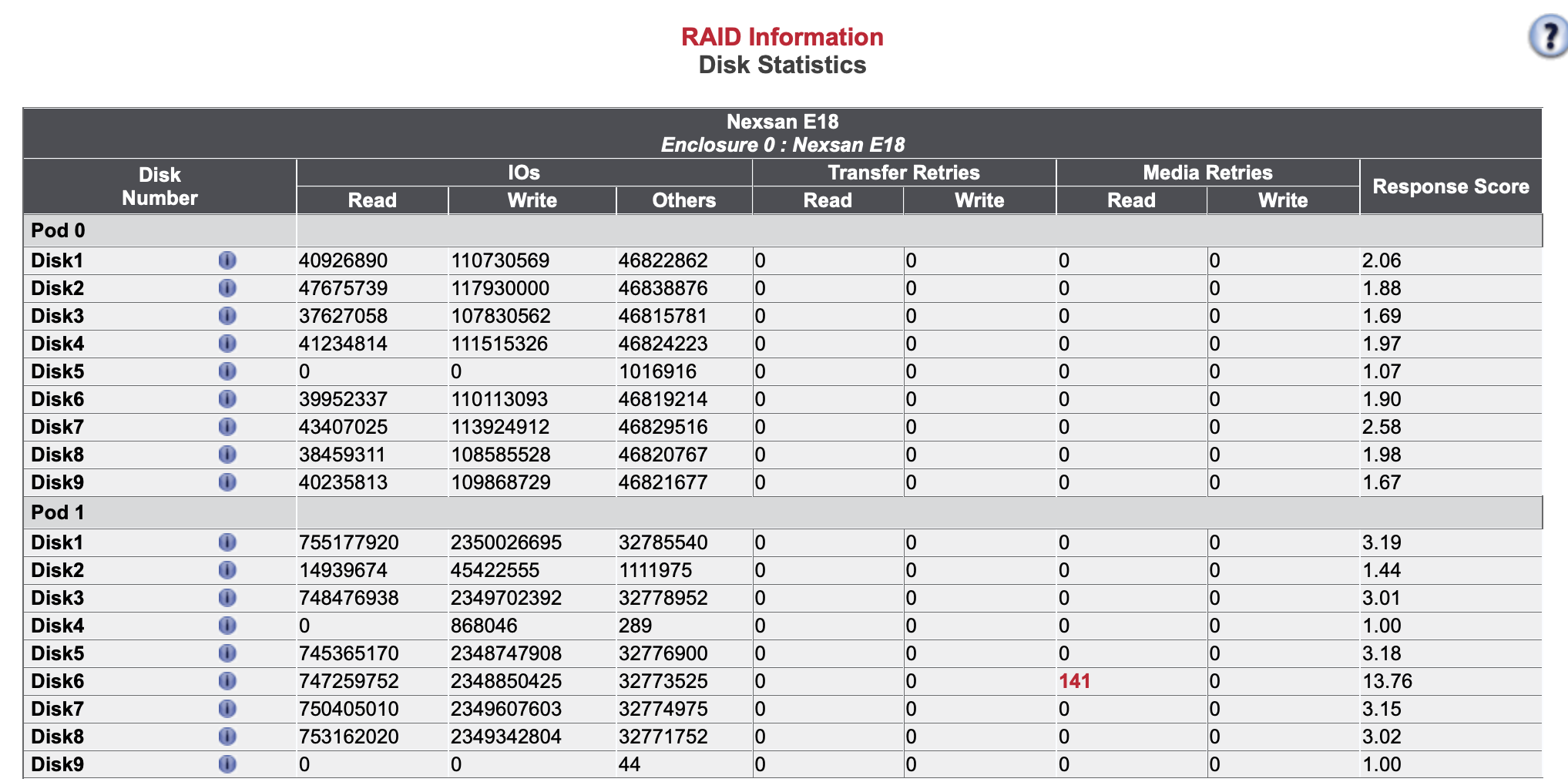
Once finished, we plan to replace Disk9 Pod1 and Disk6 Pod1 using the same procedure.



> 0000:C0 30-May-2025 at 08:29:00:(I): raid set 2 has rebuilt disk 2 pod 1 (L3)
The rebuild took 37 hours.
[YamaT-san, Ikeda]
This is work related to K-Log#33393.
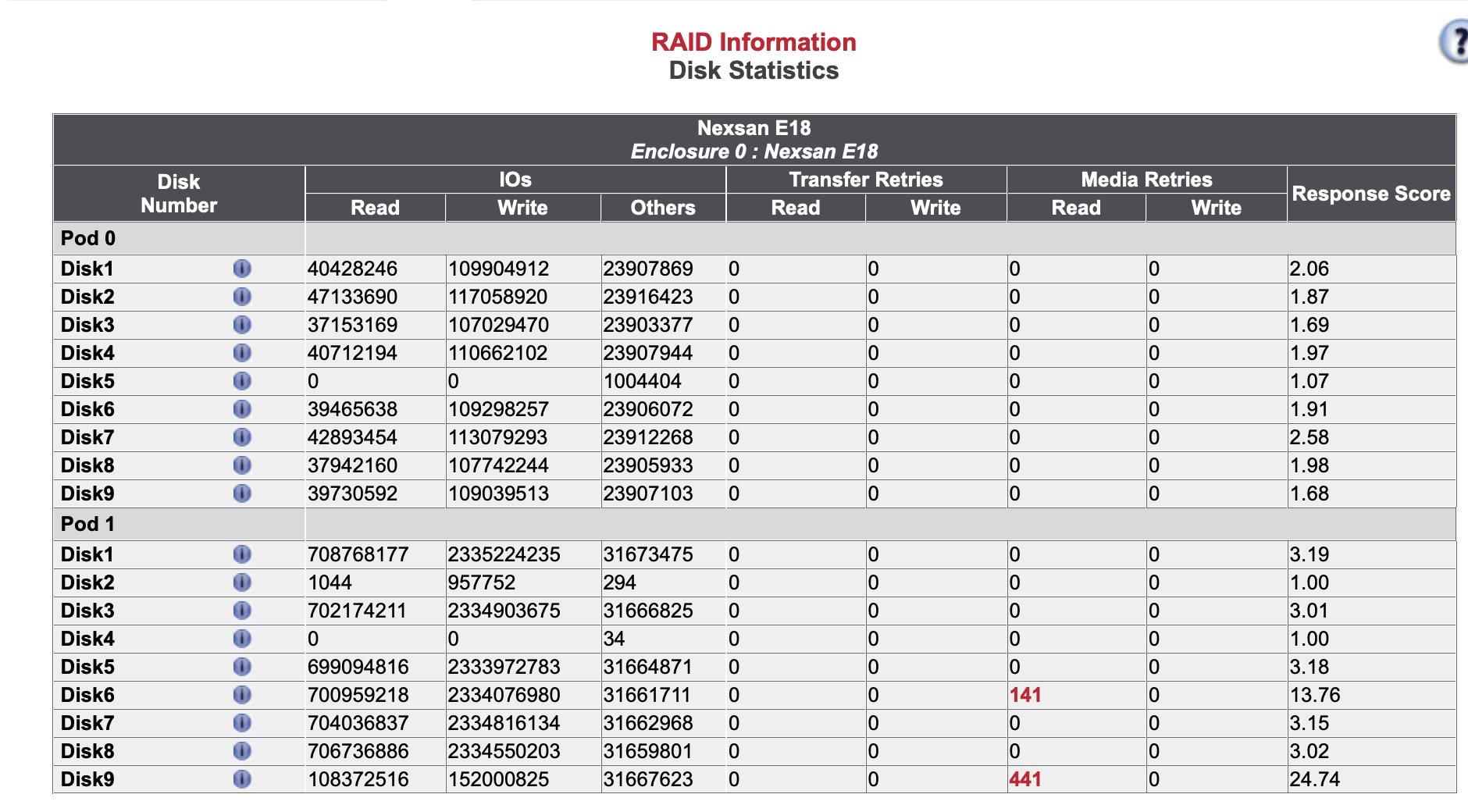
We have replaced the HDD on Disk9 Pod1.
Disk6 Pod1 will not be replaced now.
If the number of errors increases, it will be replaced.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1154 mine in
1157 server room in
1158 disk array open
1200 forced fail
1201 disk replace
1202 add hot spare
1203 disk array close
1204 fix ntp TZ
1206 server room out
1208 mine out