Abstract
I prepared a new guardian code in order to skip the initial check of lockloss investigation.Because it's now working on an unused guardian node (CAL_PROC), I will move it on a new guardian node with a proper name in the next maintenance day.
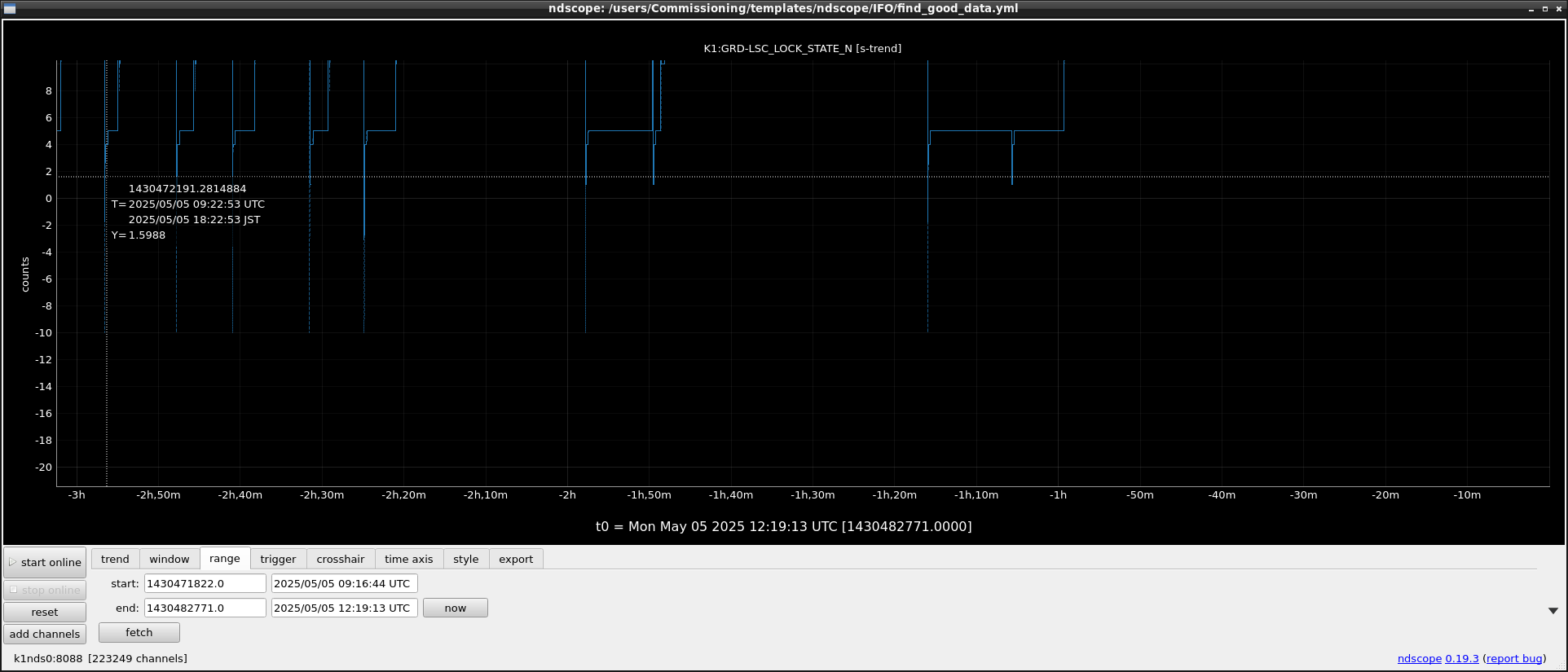
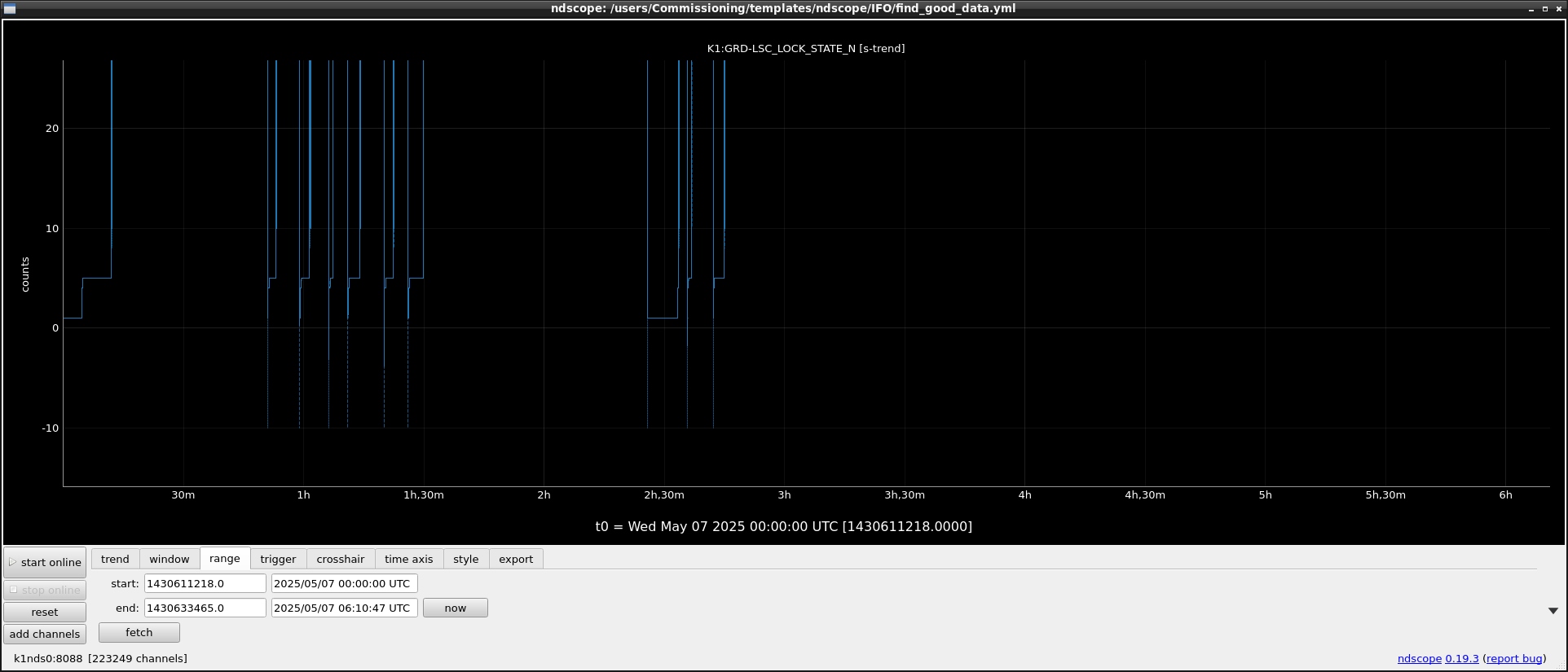
Initial check results are available on /users/Commissioning/data/lockloss/yyyy/mmdd/yyyy-mm-dd.json.
Details
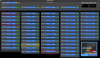
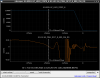
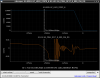
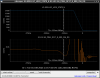
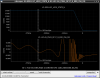
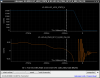
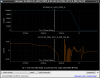
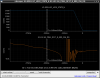
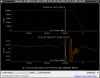
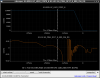
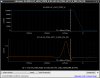
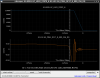
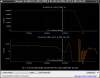
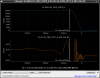
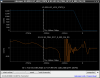
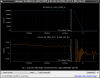
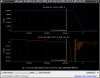
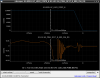
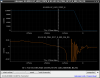
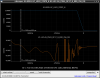
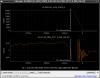
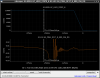
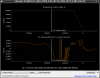
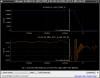
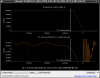
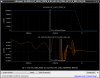
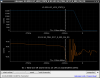
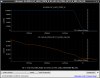
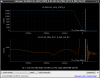
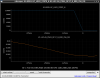
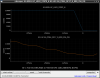
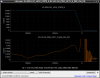
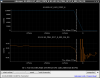
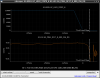
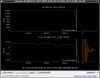
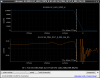
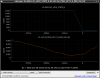
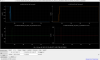
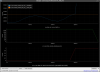
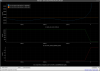
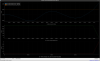
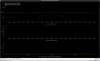
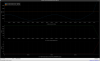
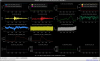
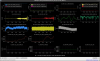
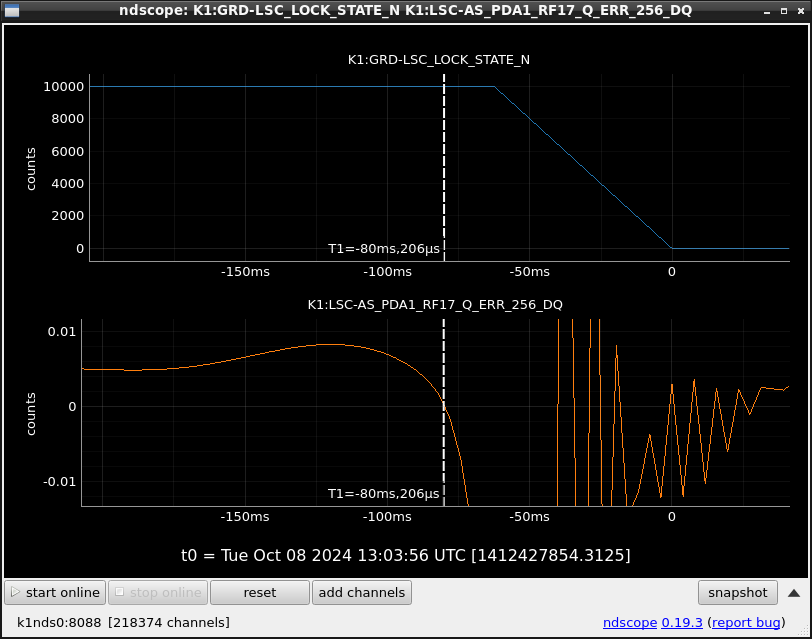
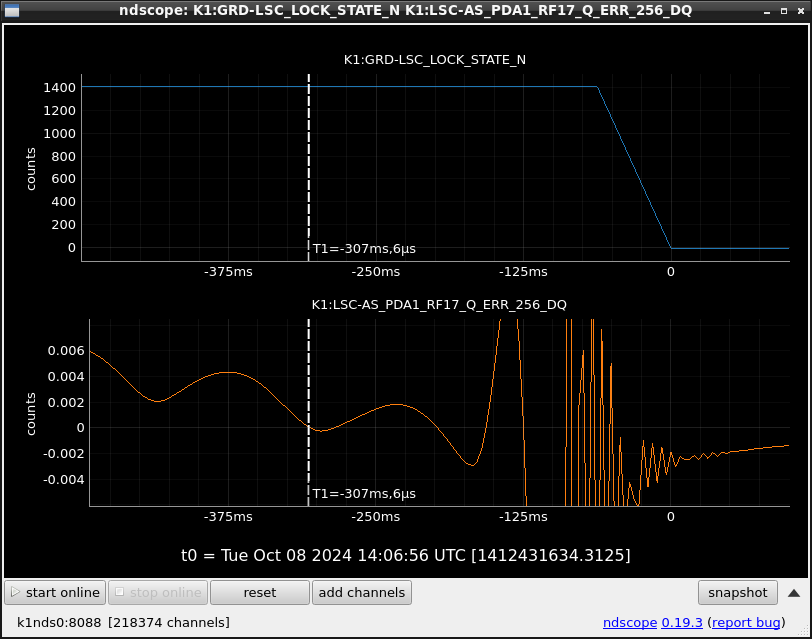
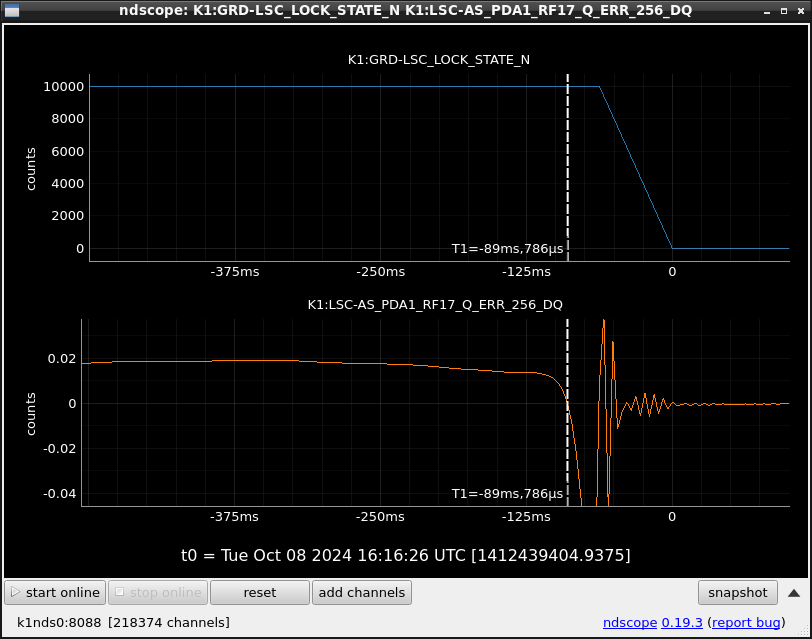
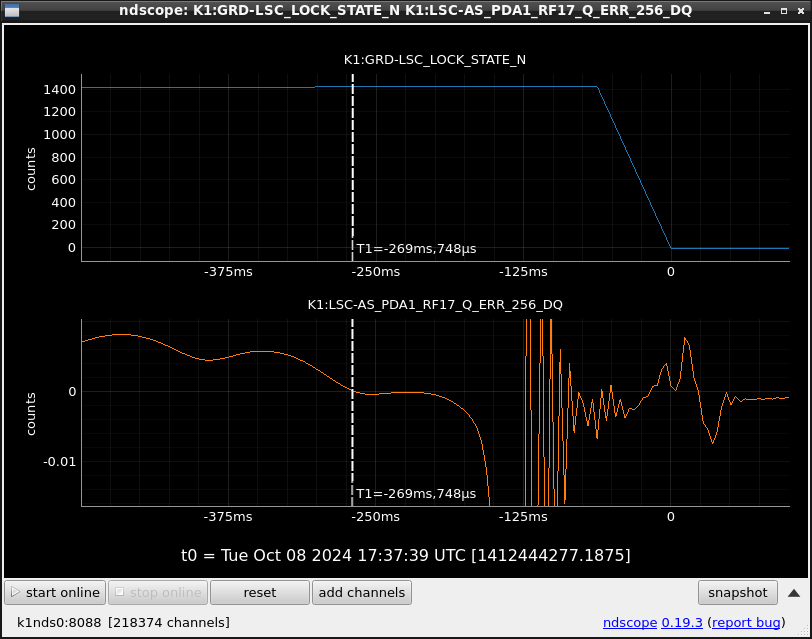
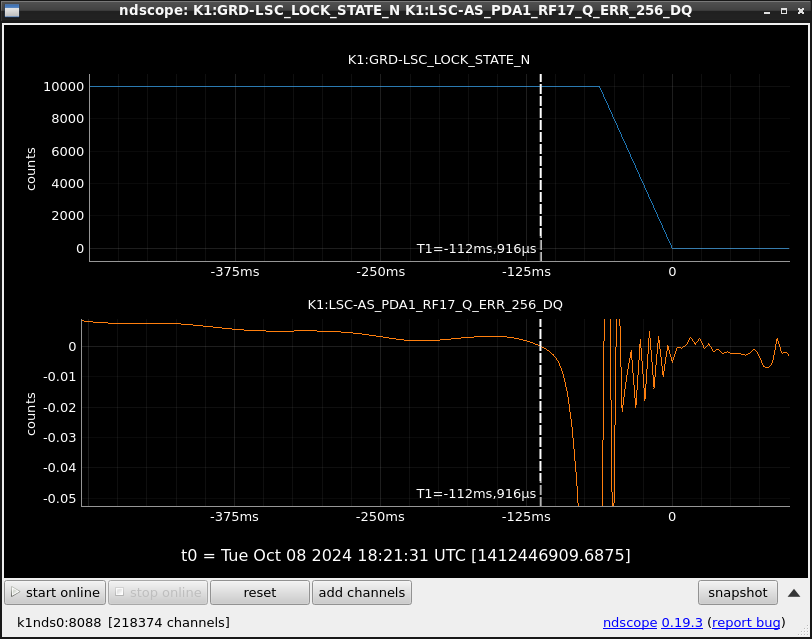
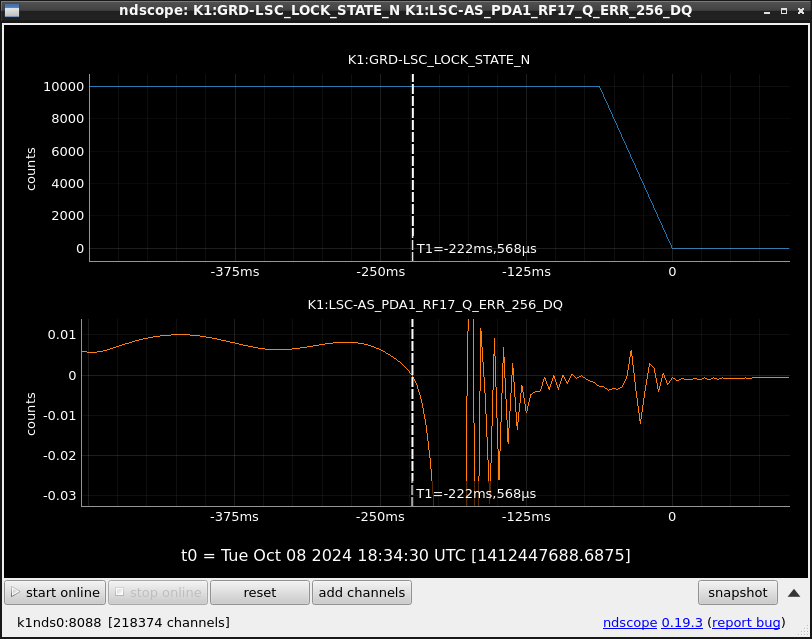
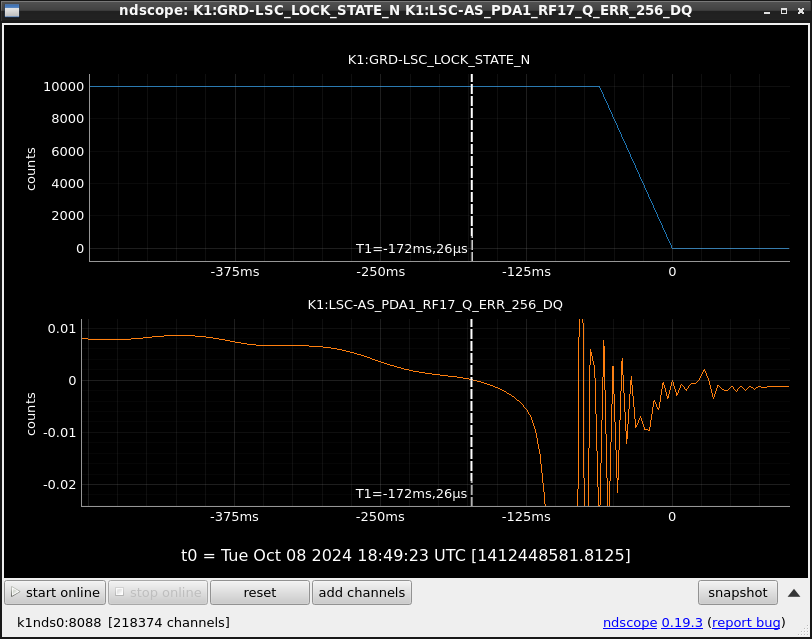
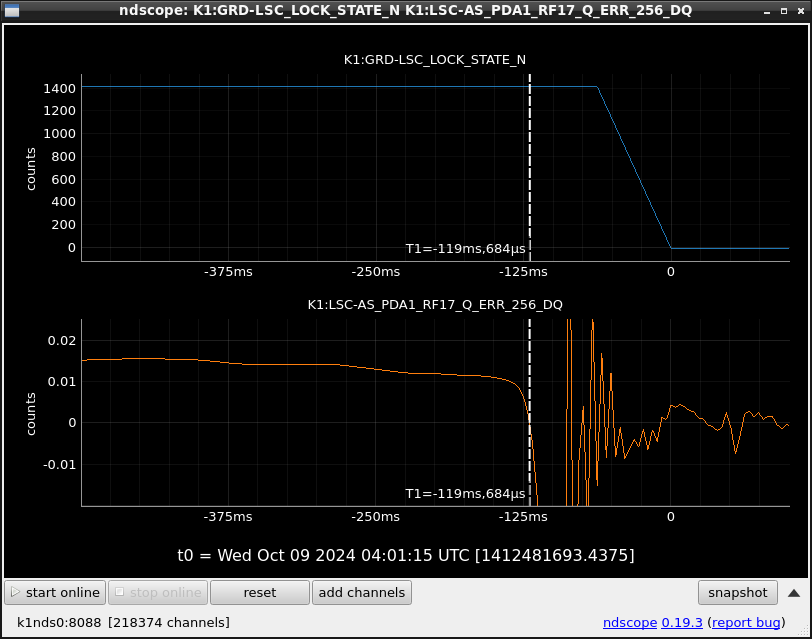
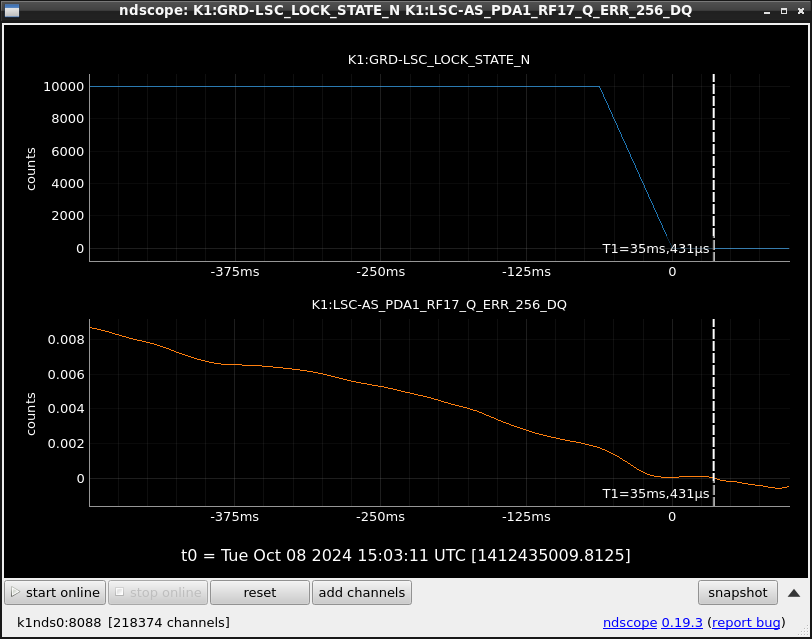
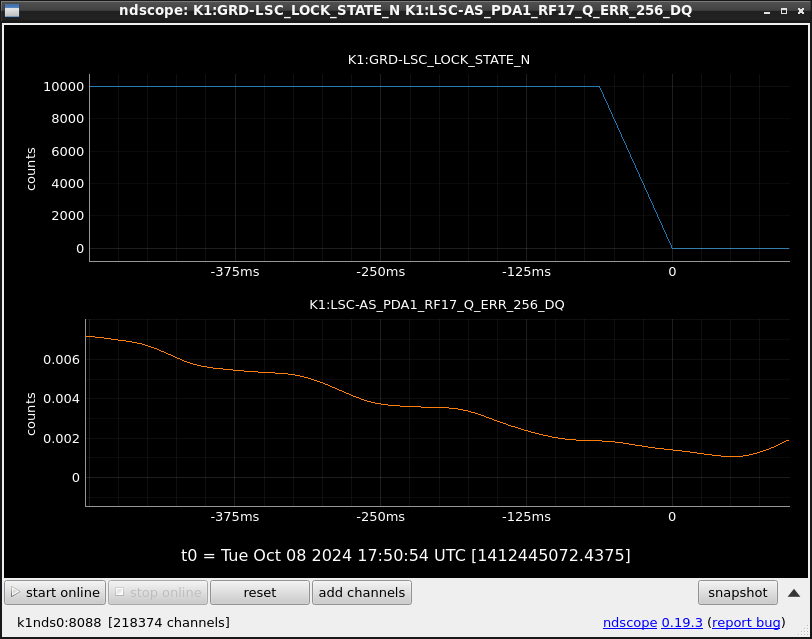
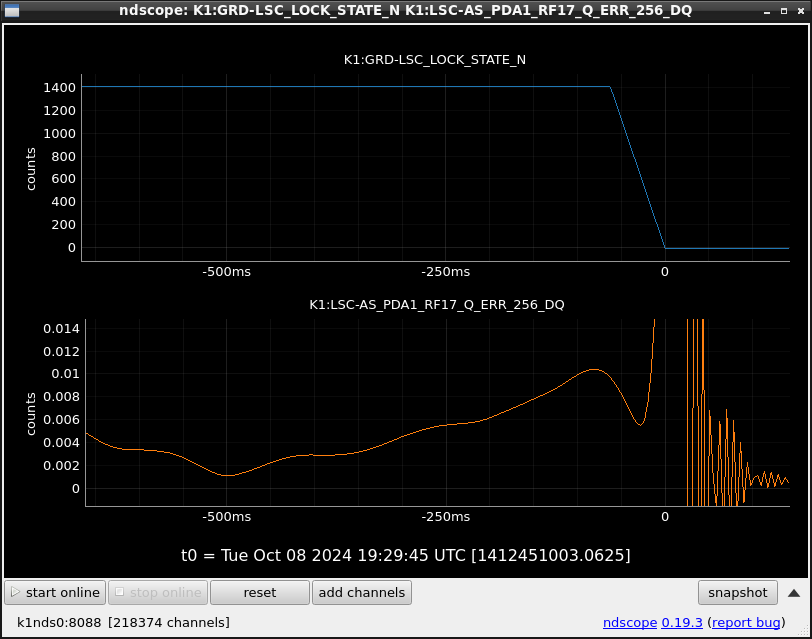
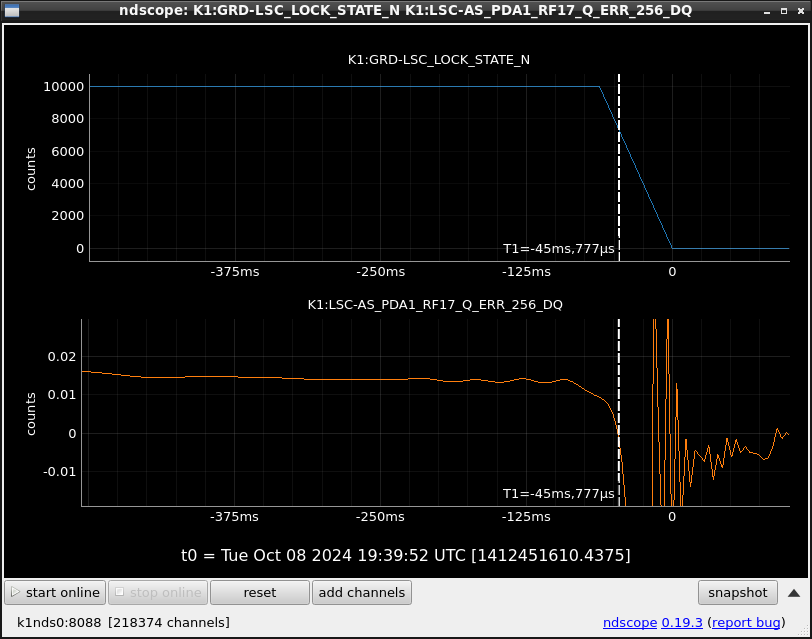
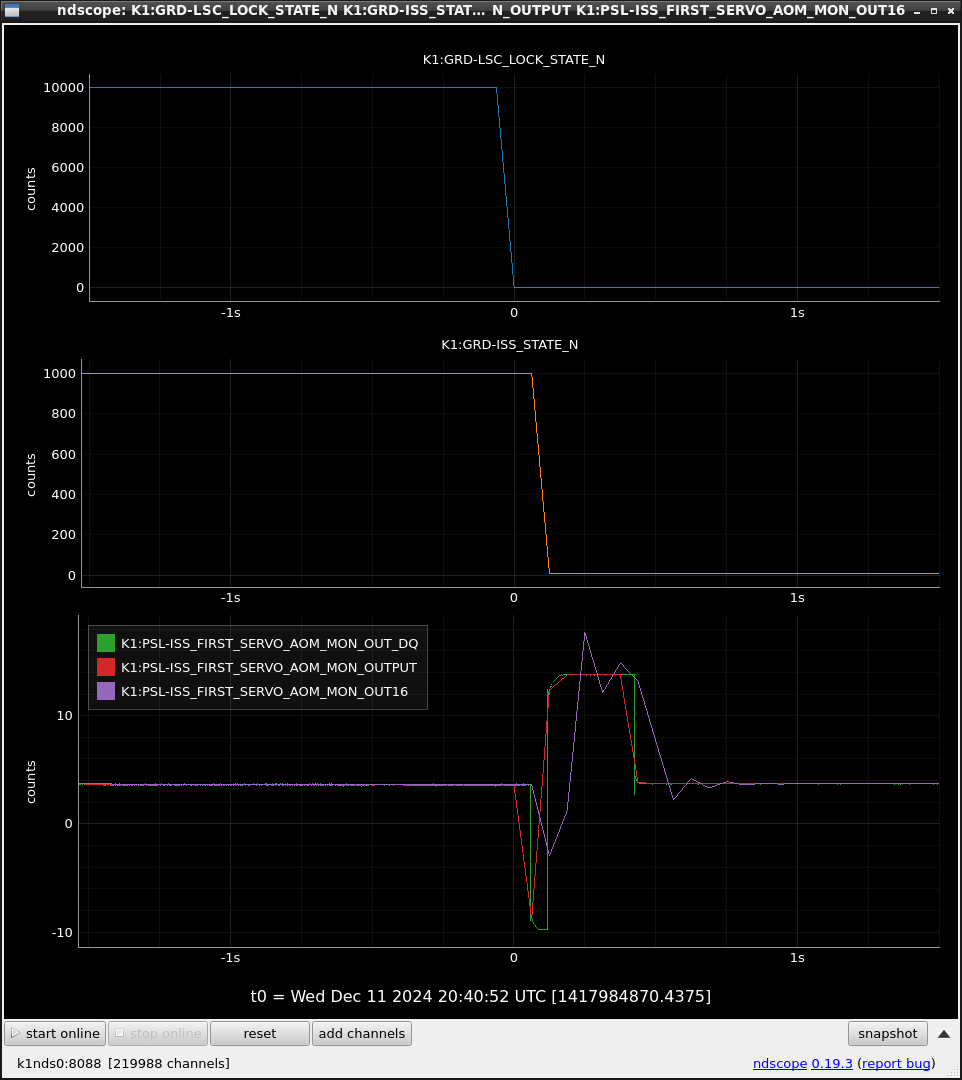
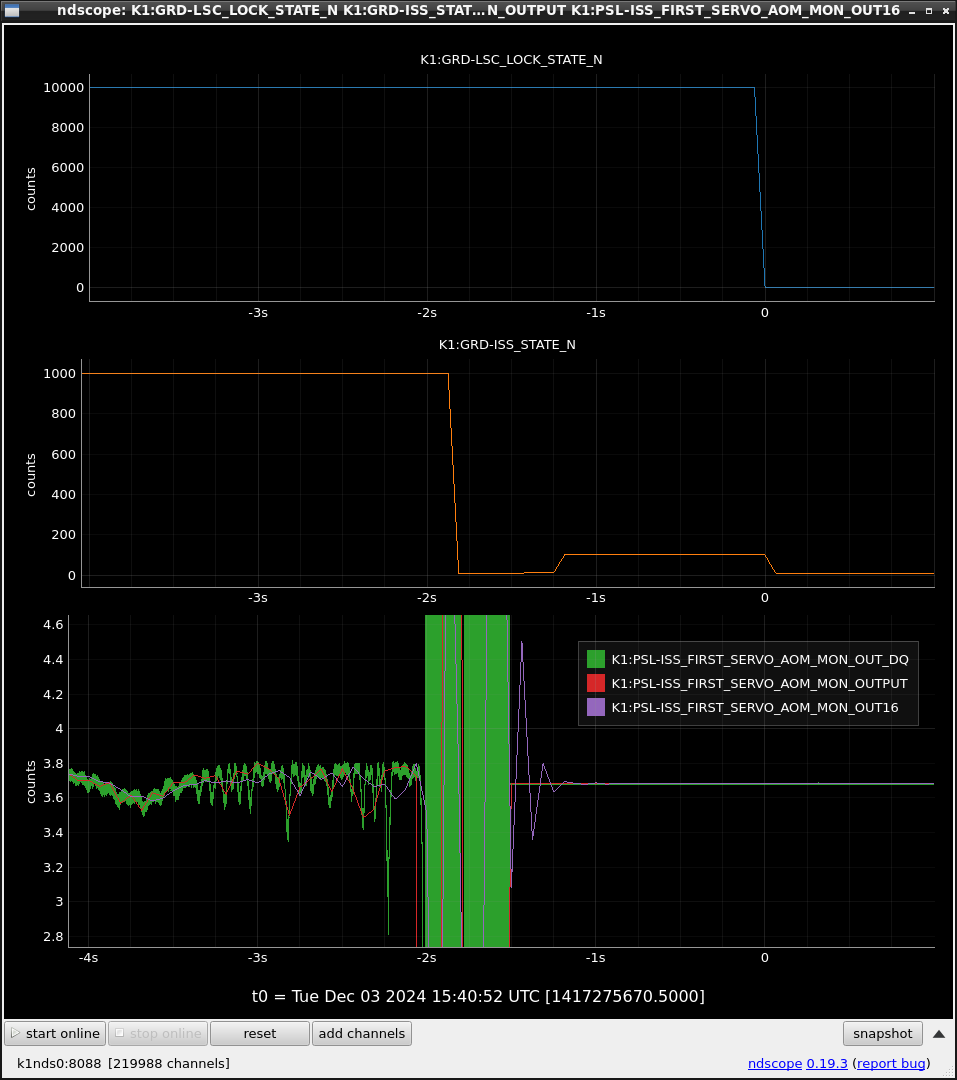
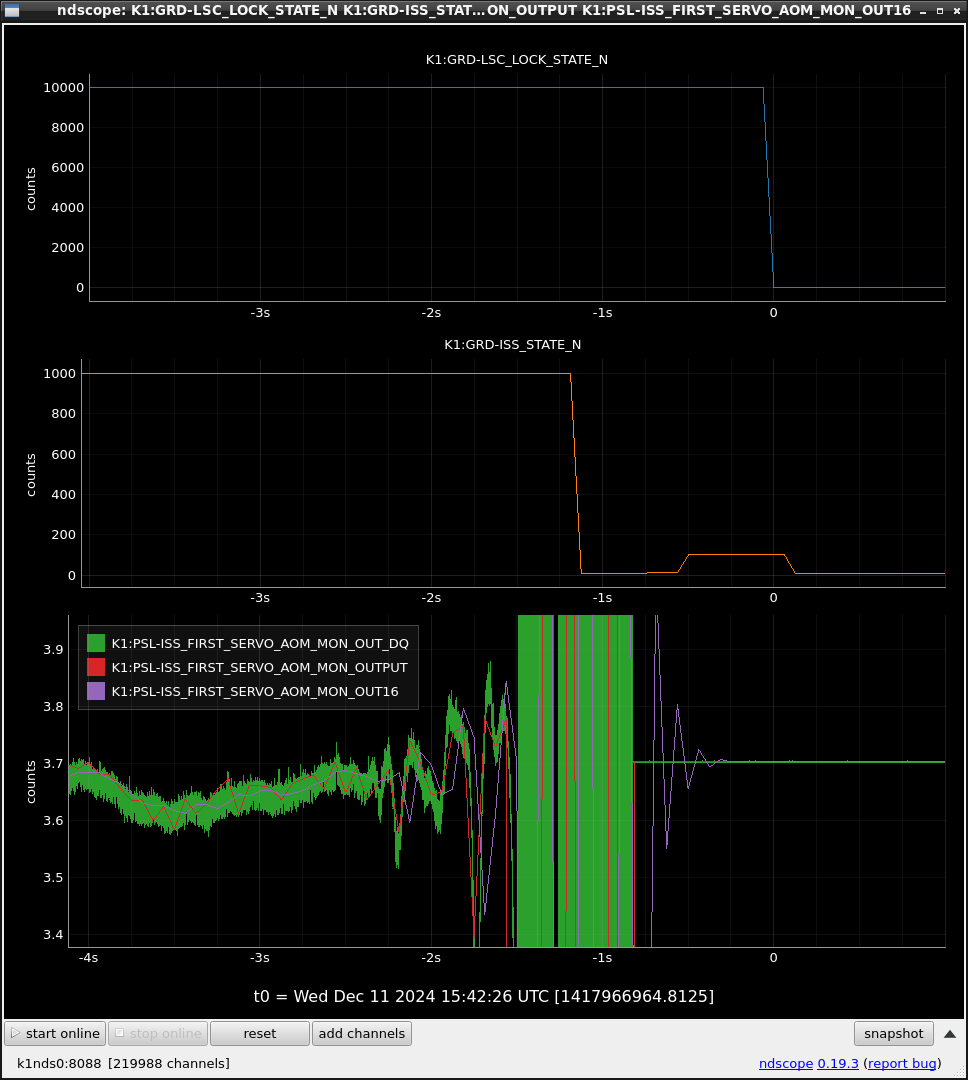
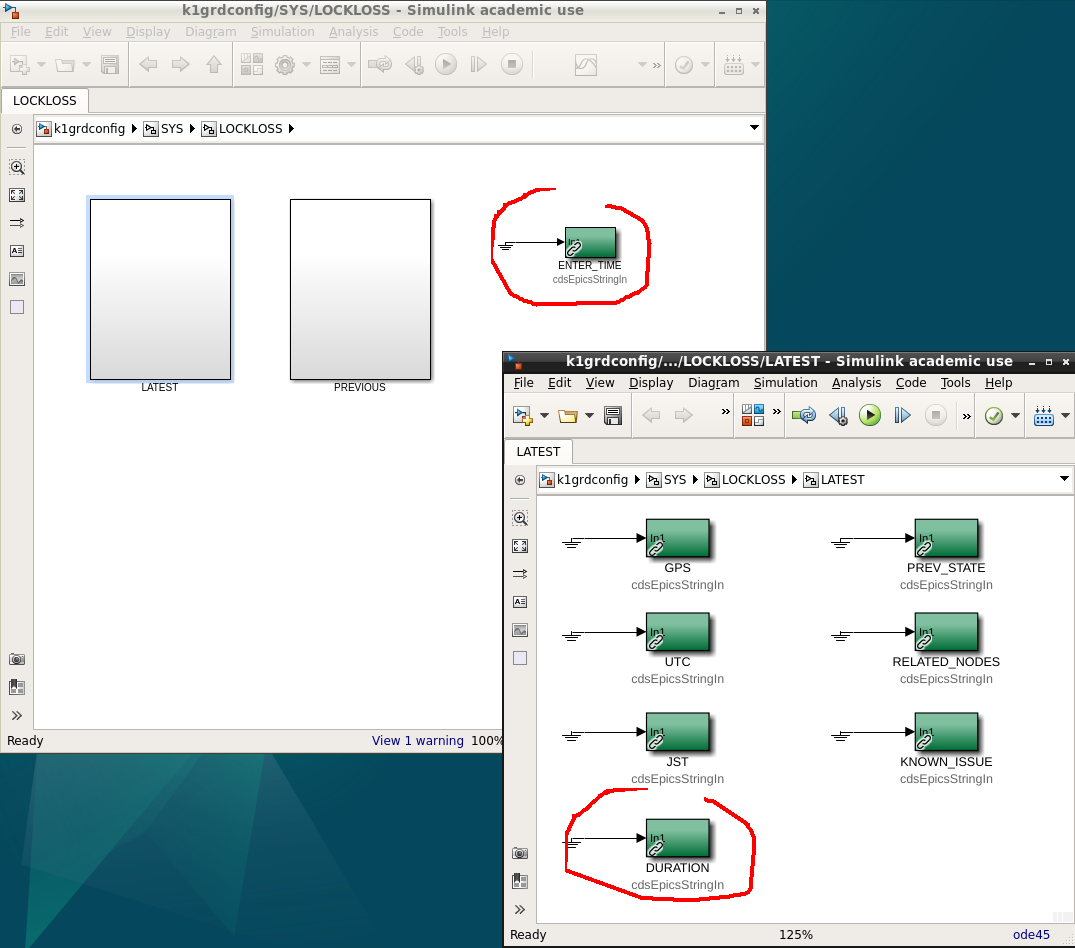
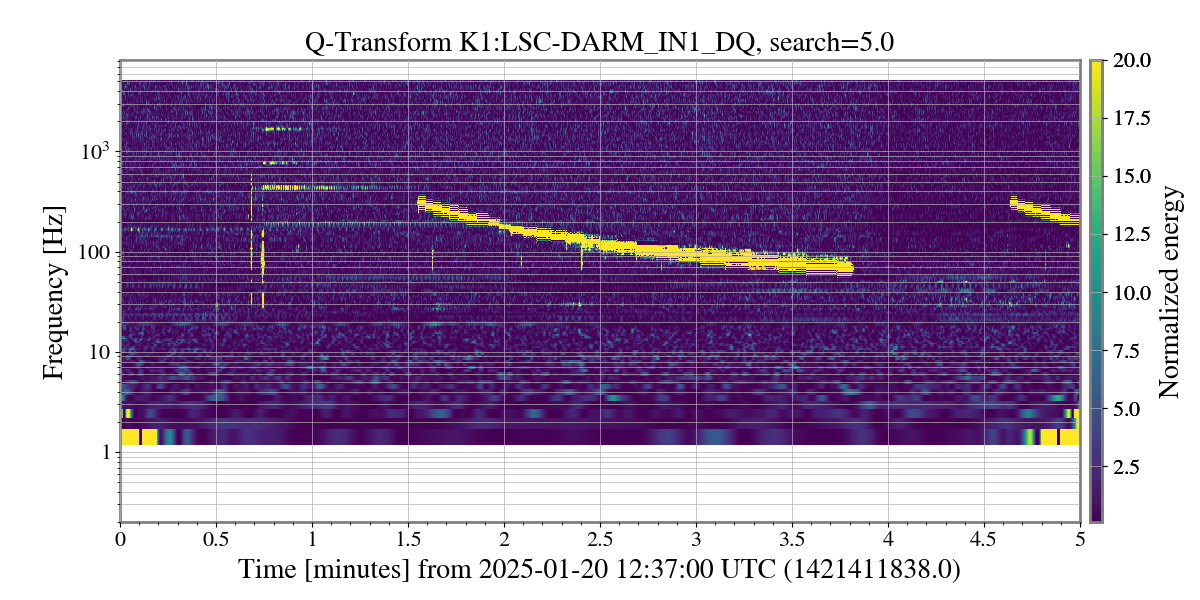
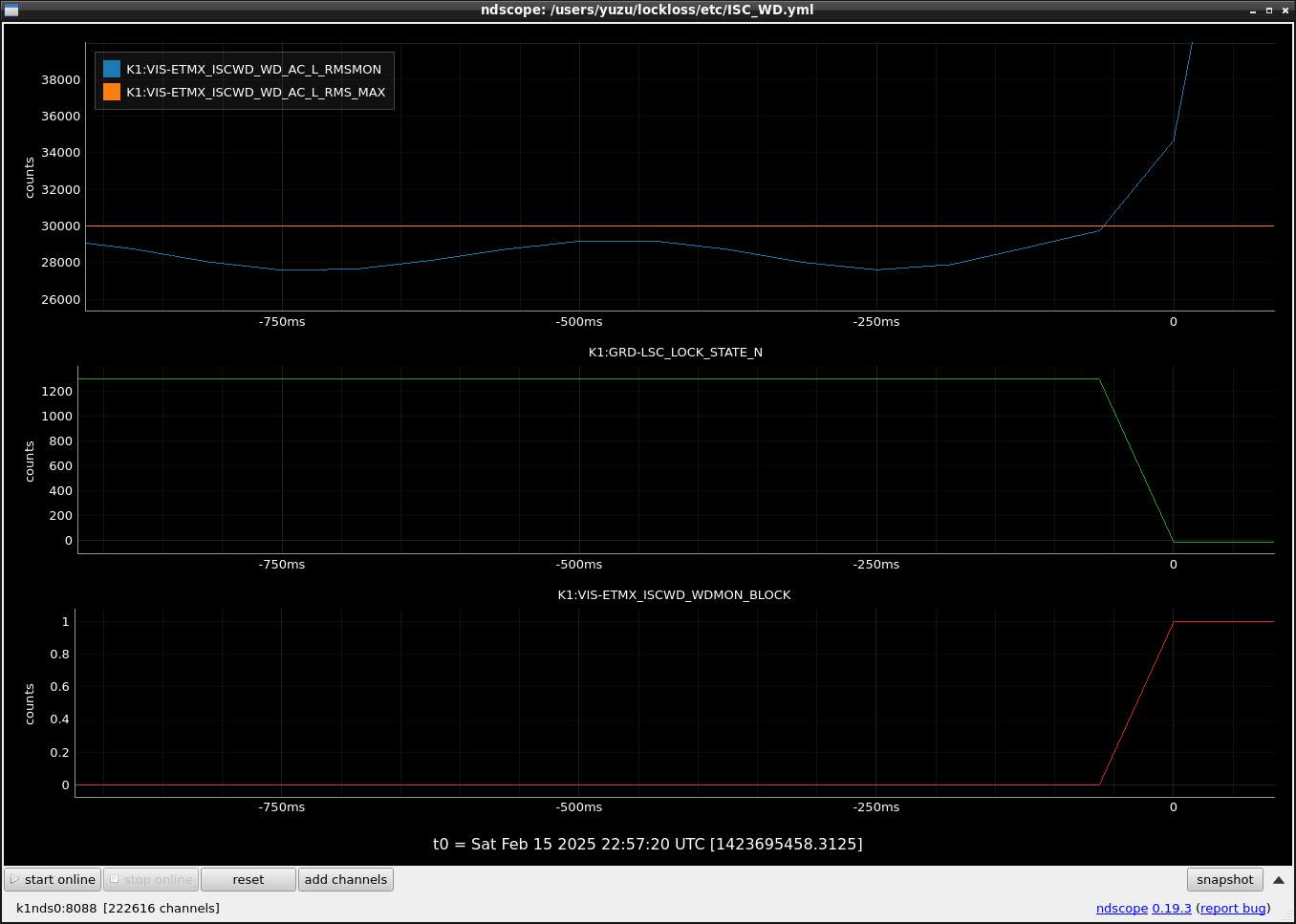
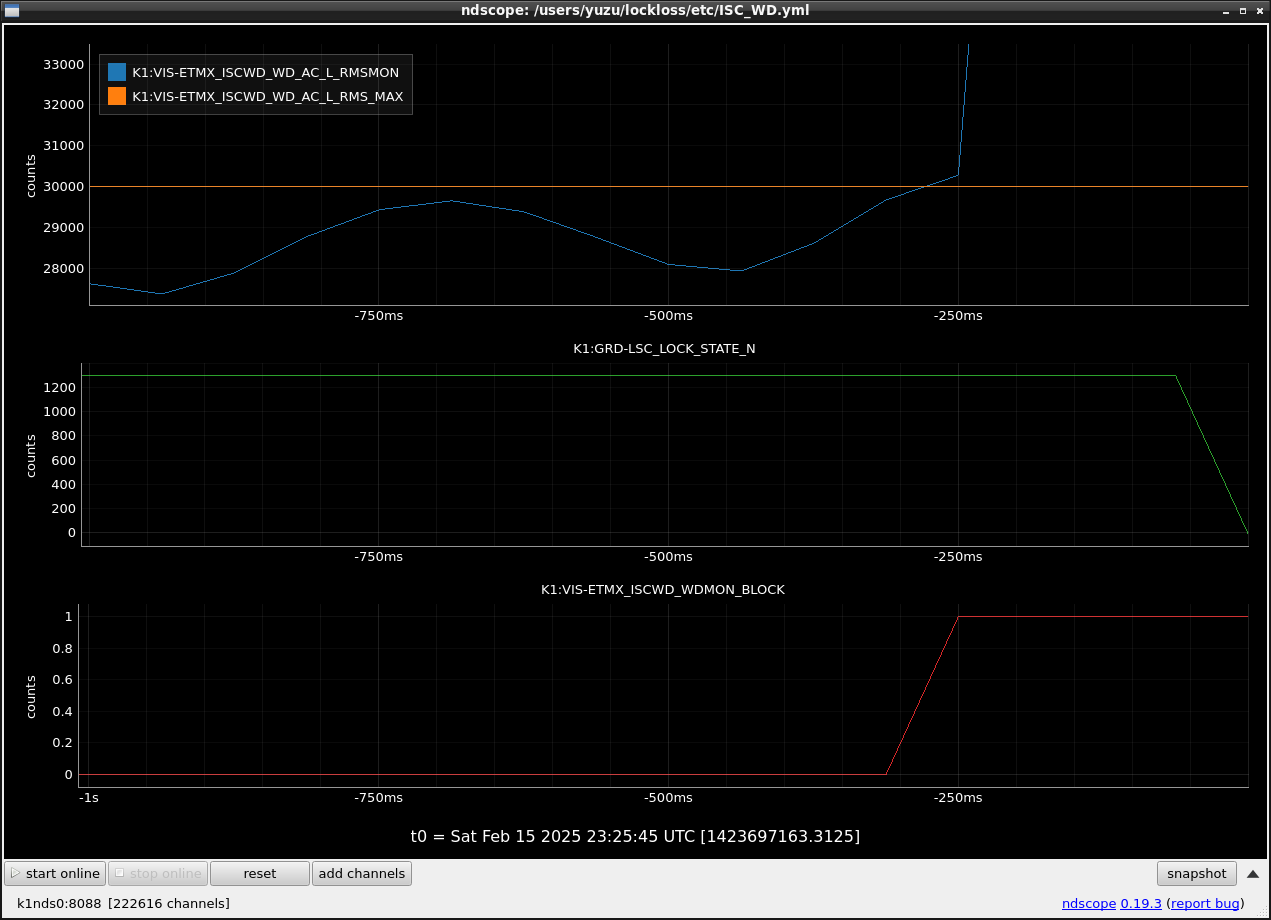
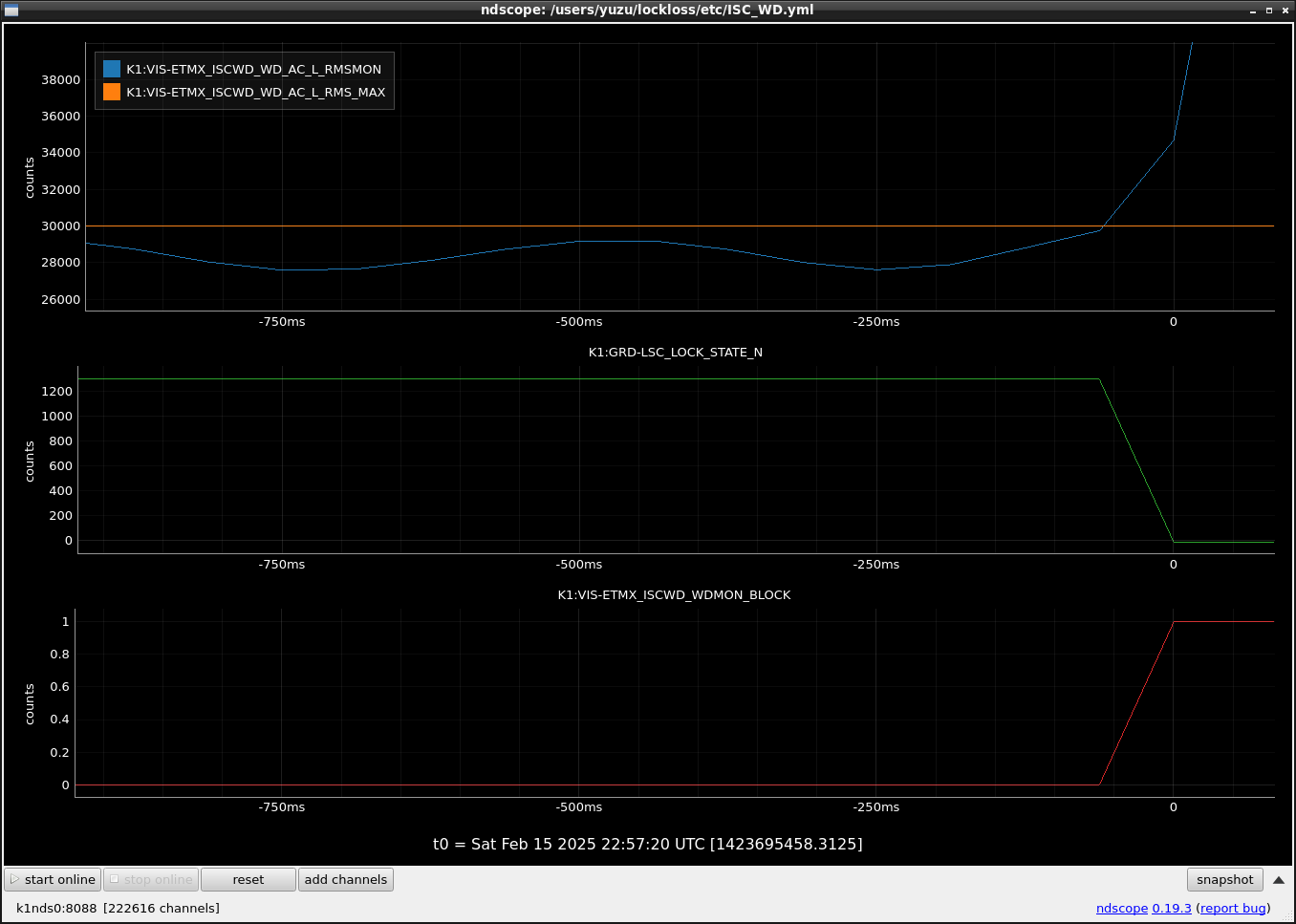
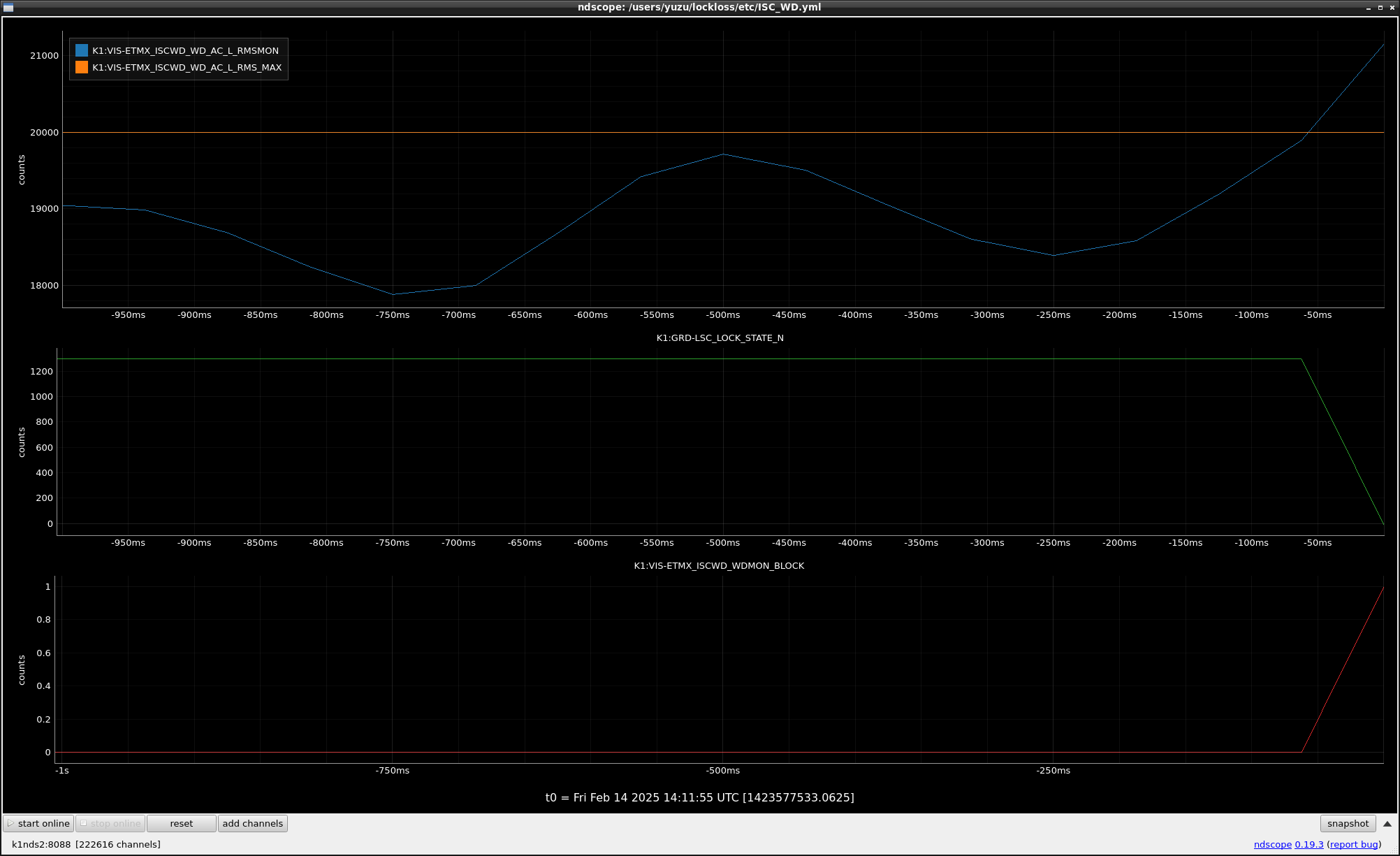
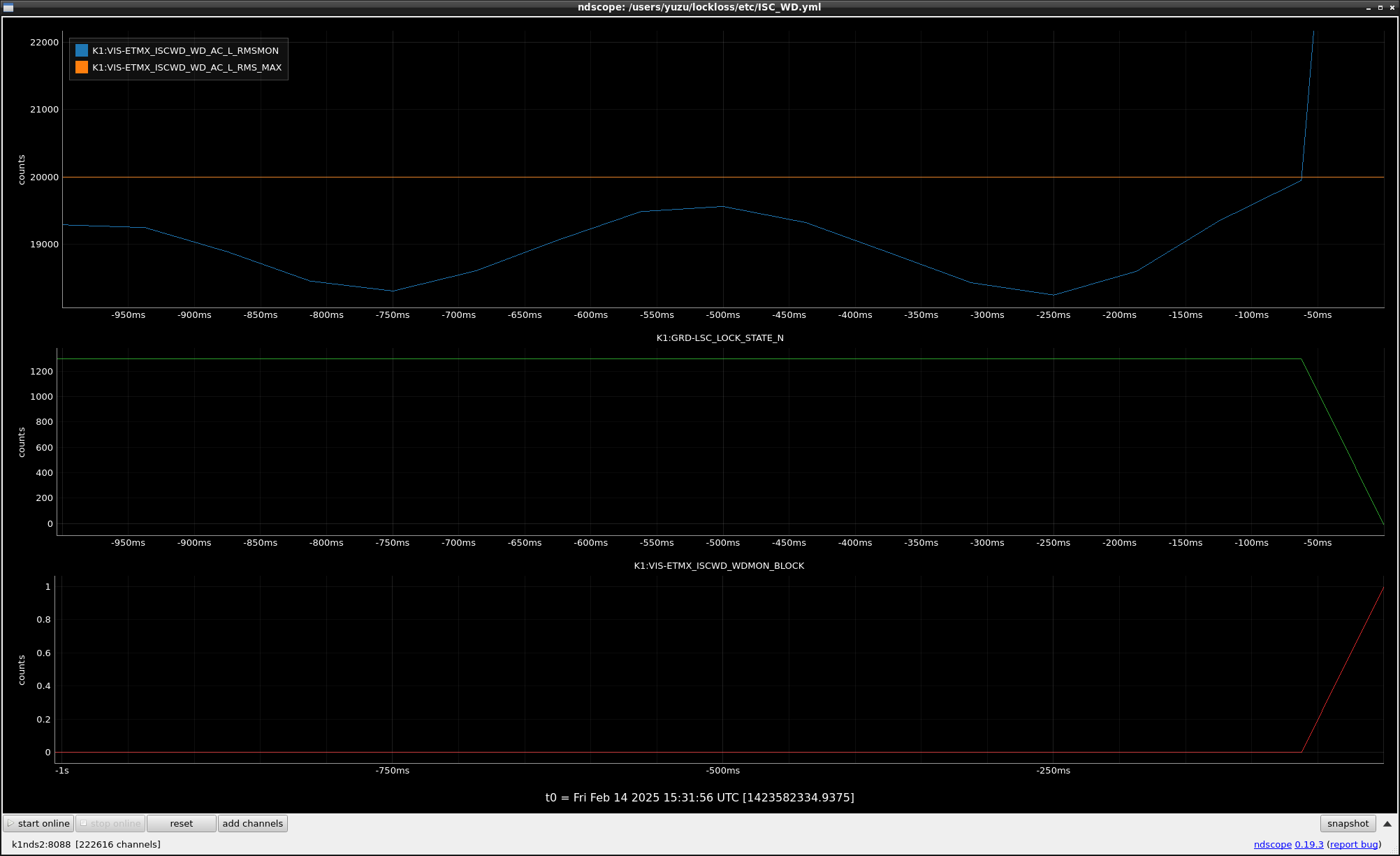
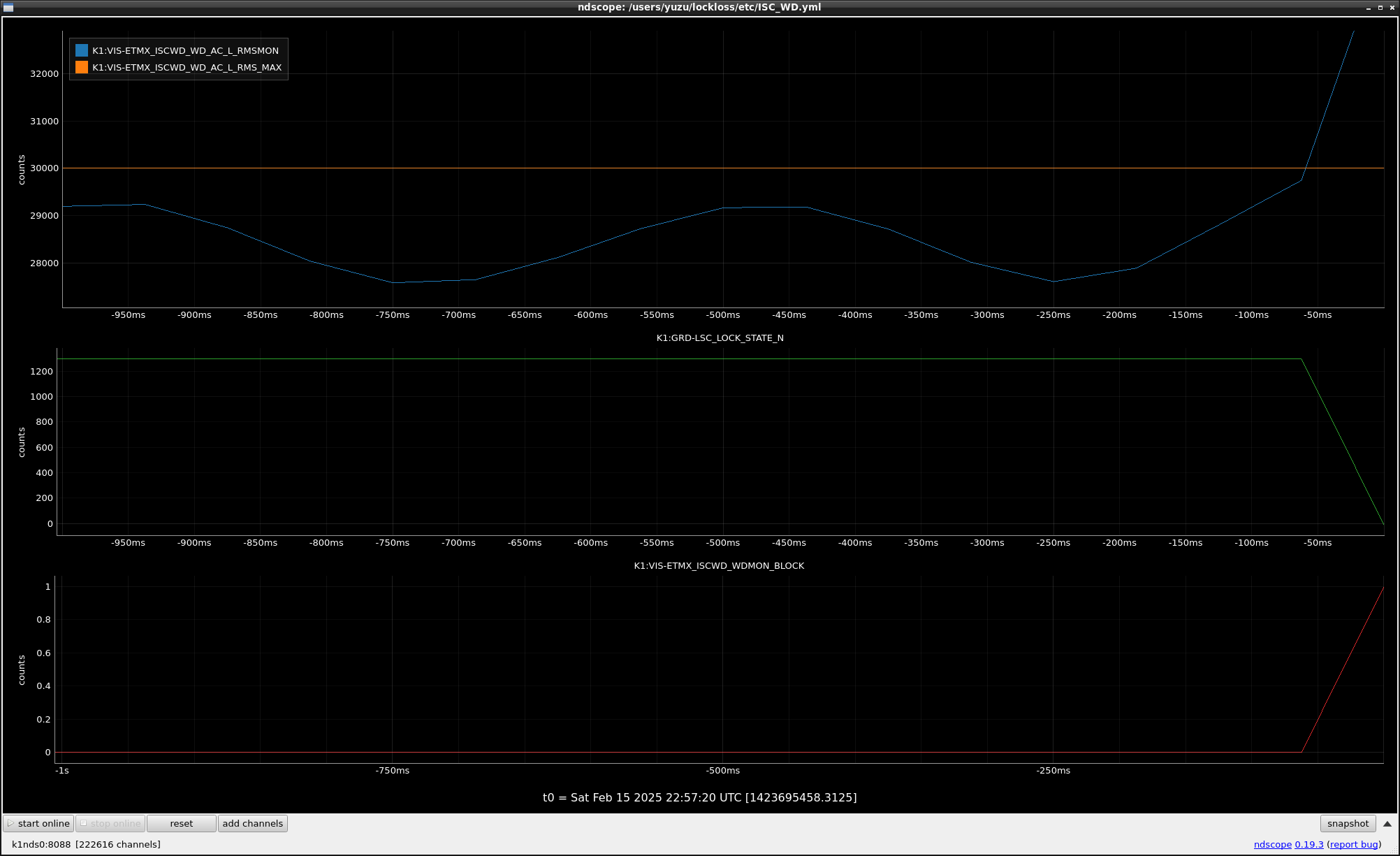
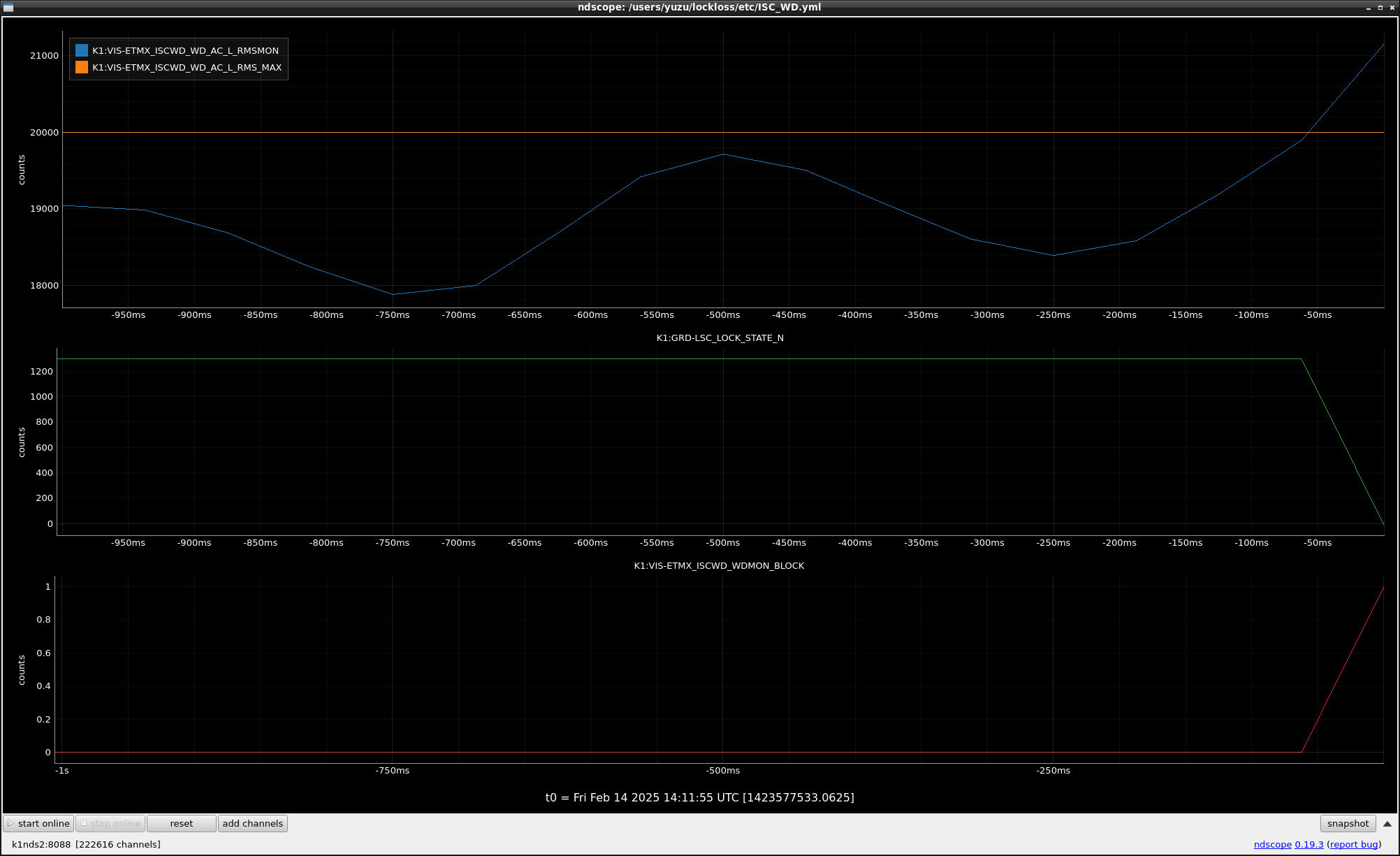
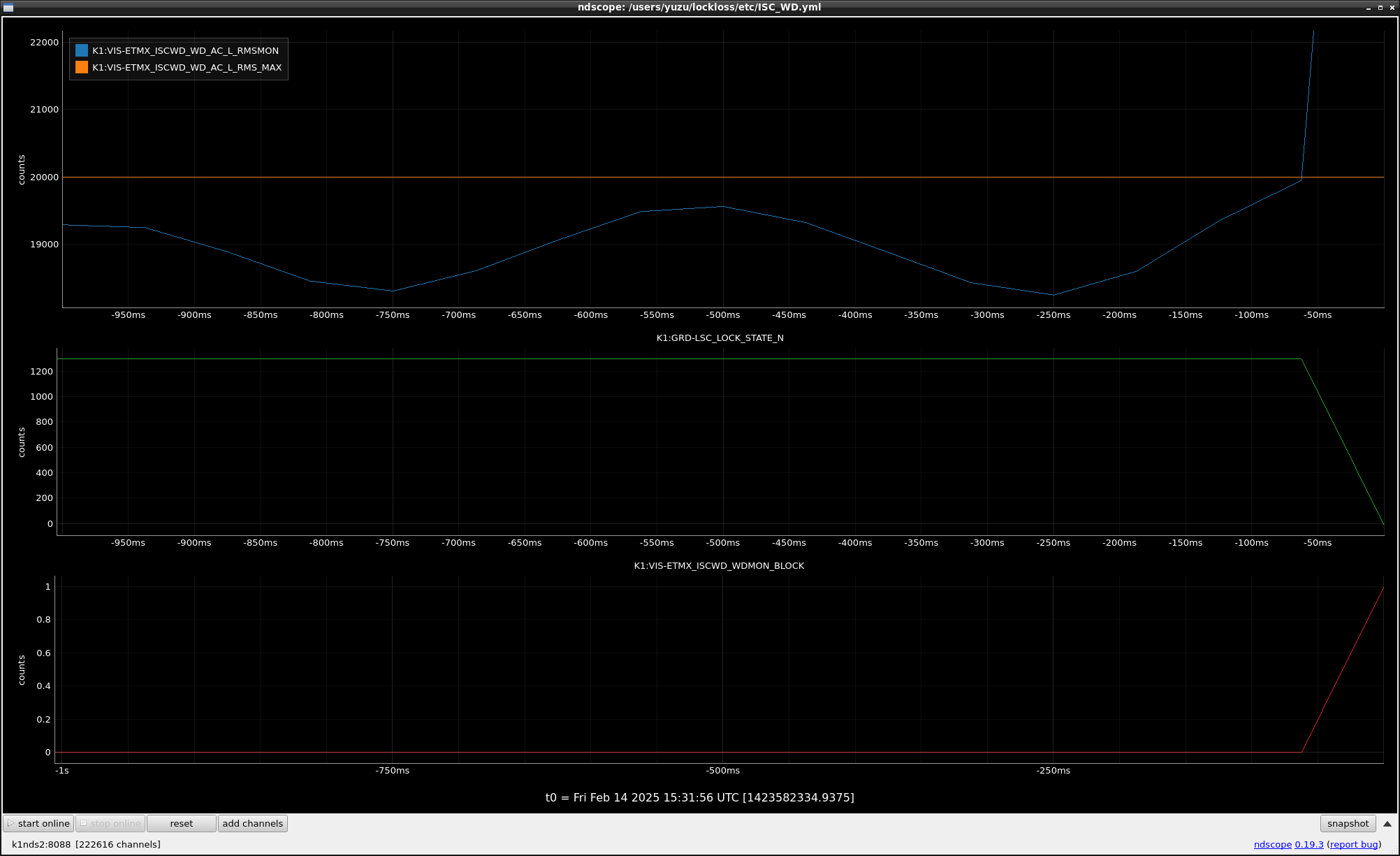
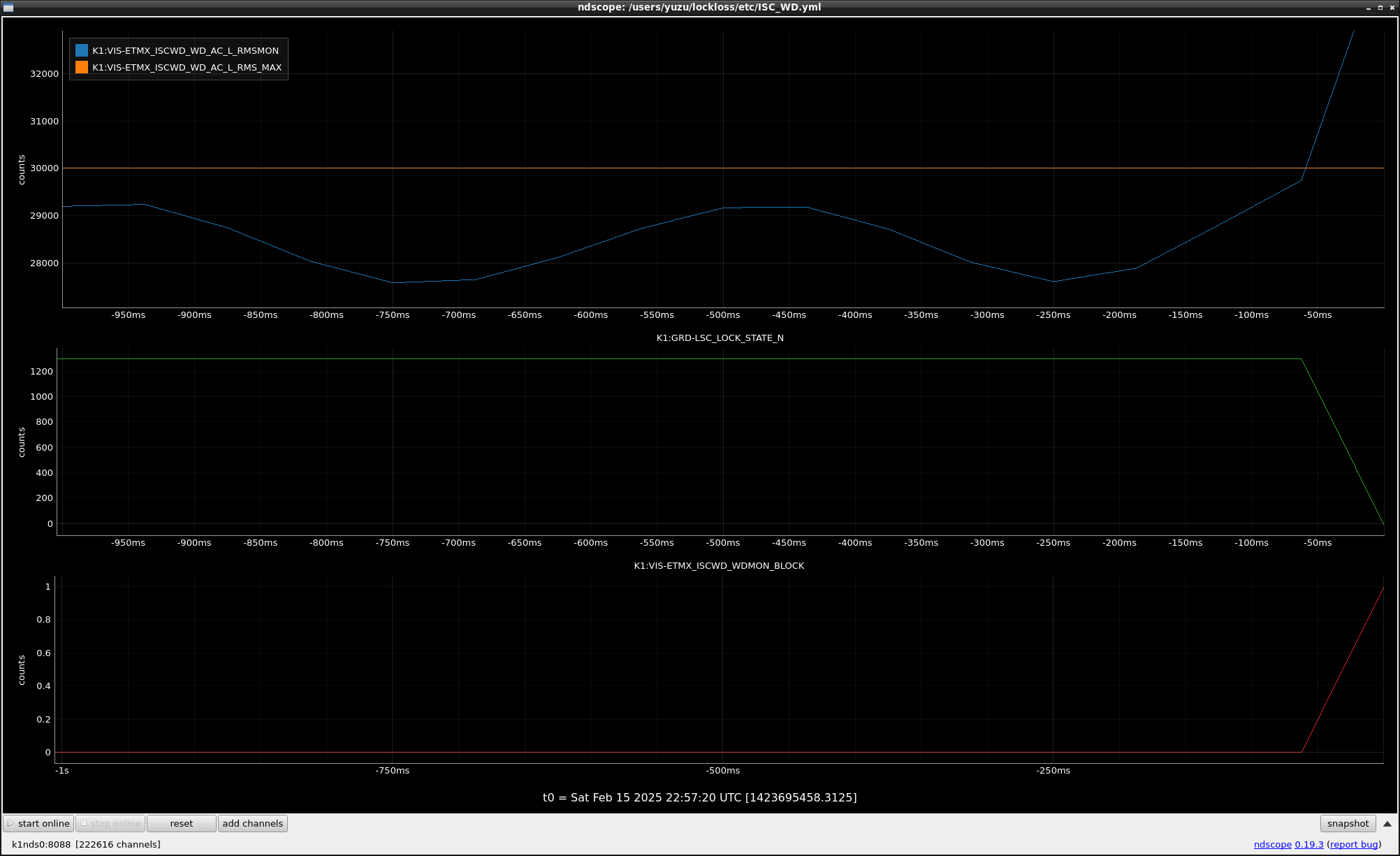
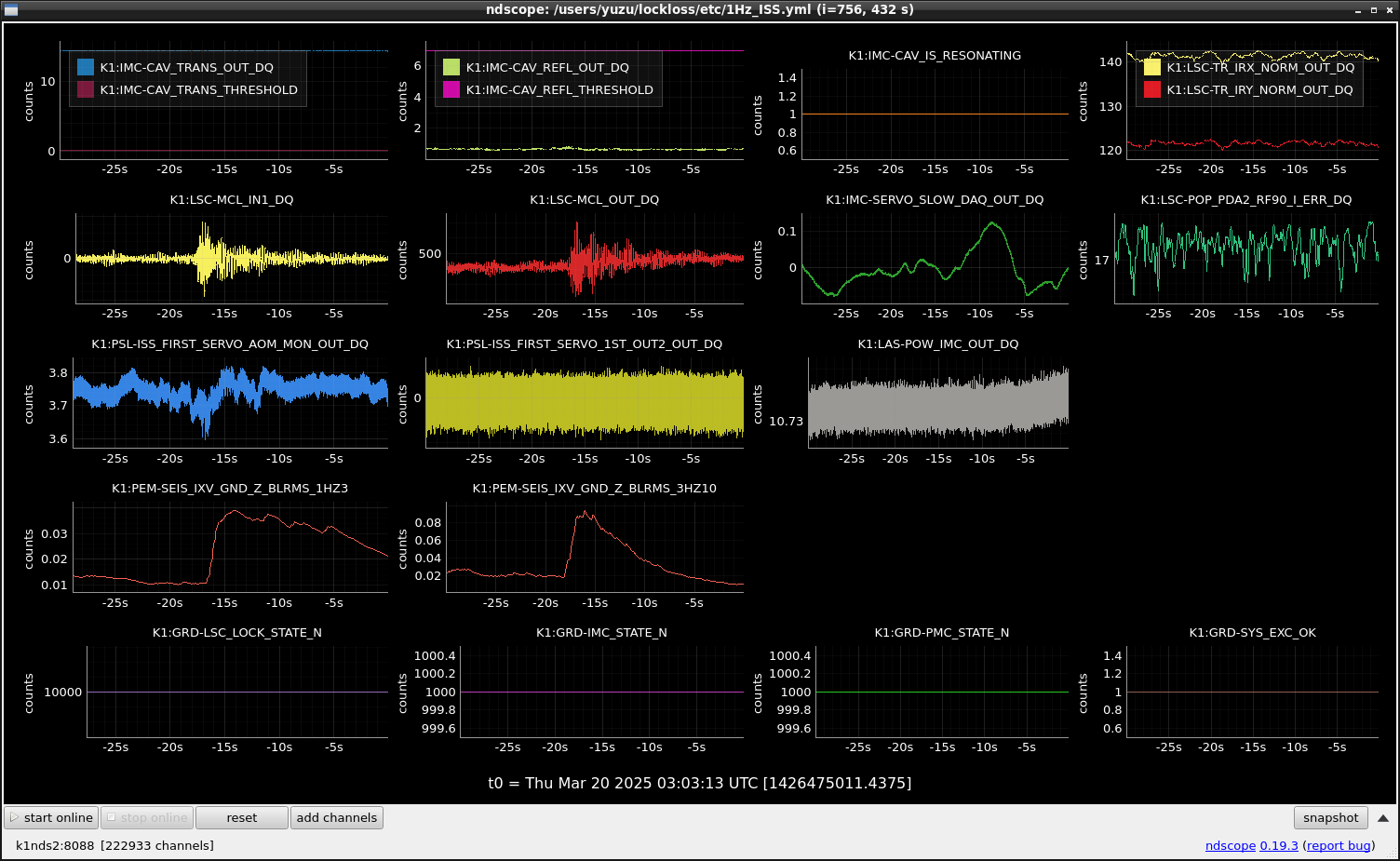
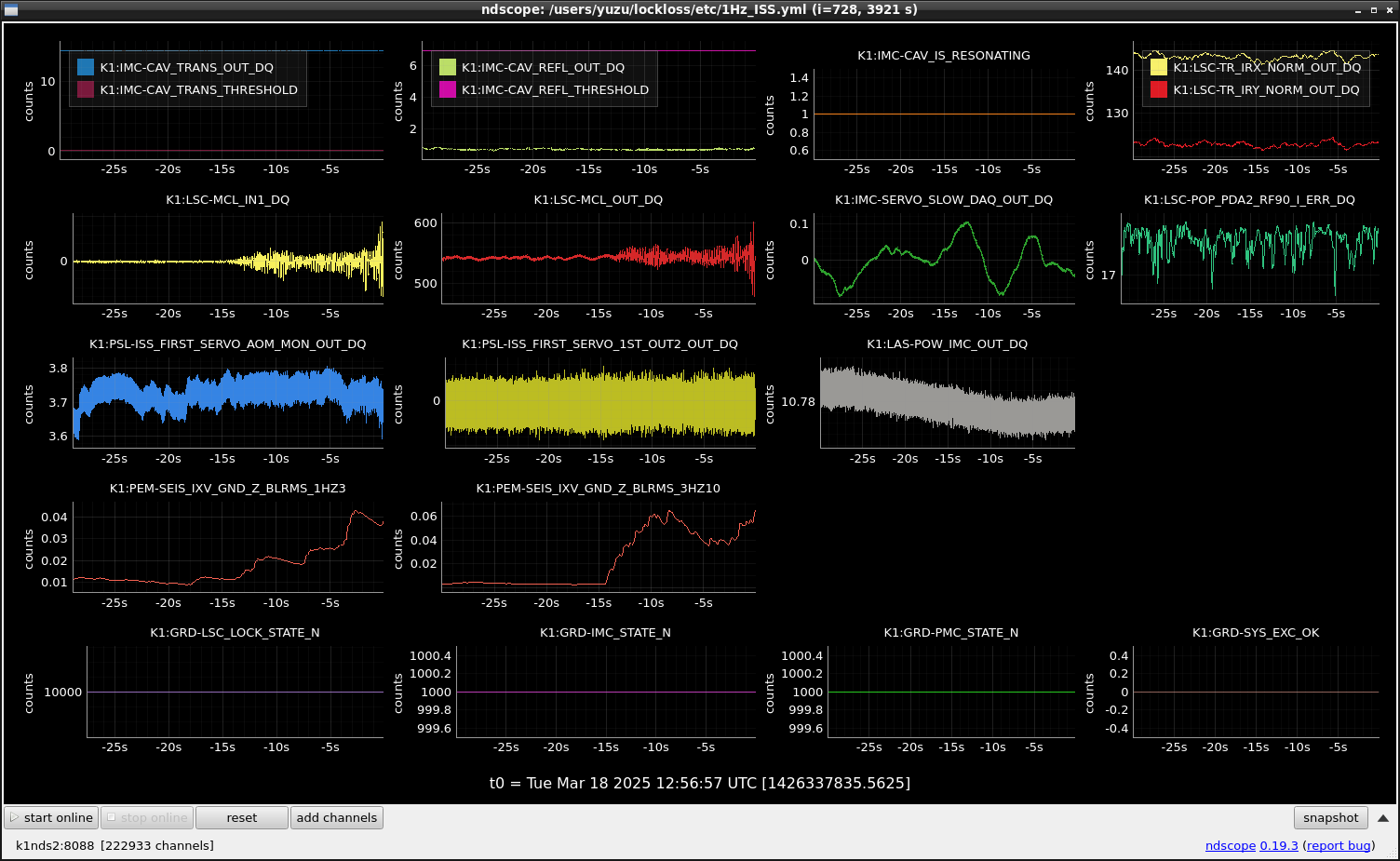
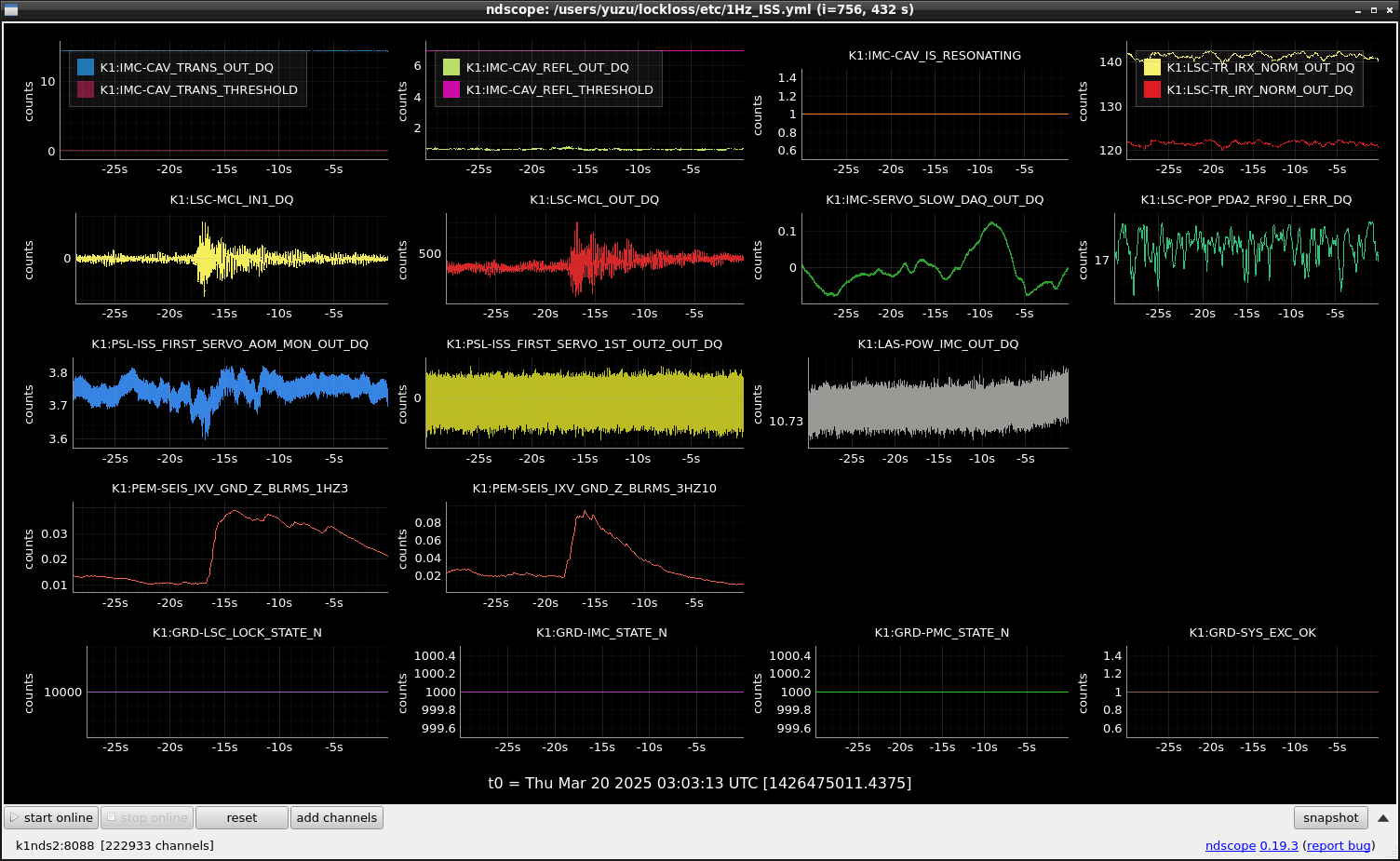
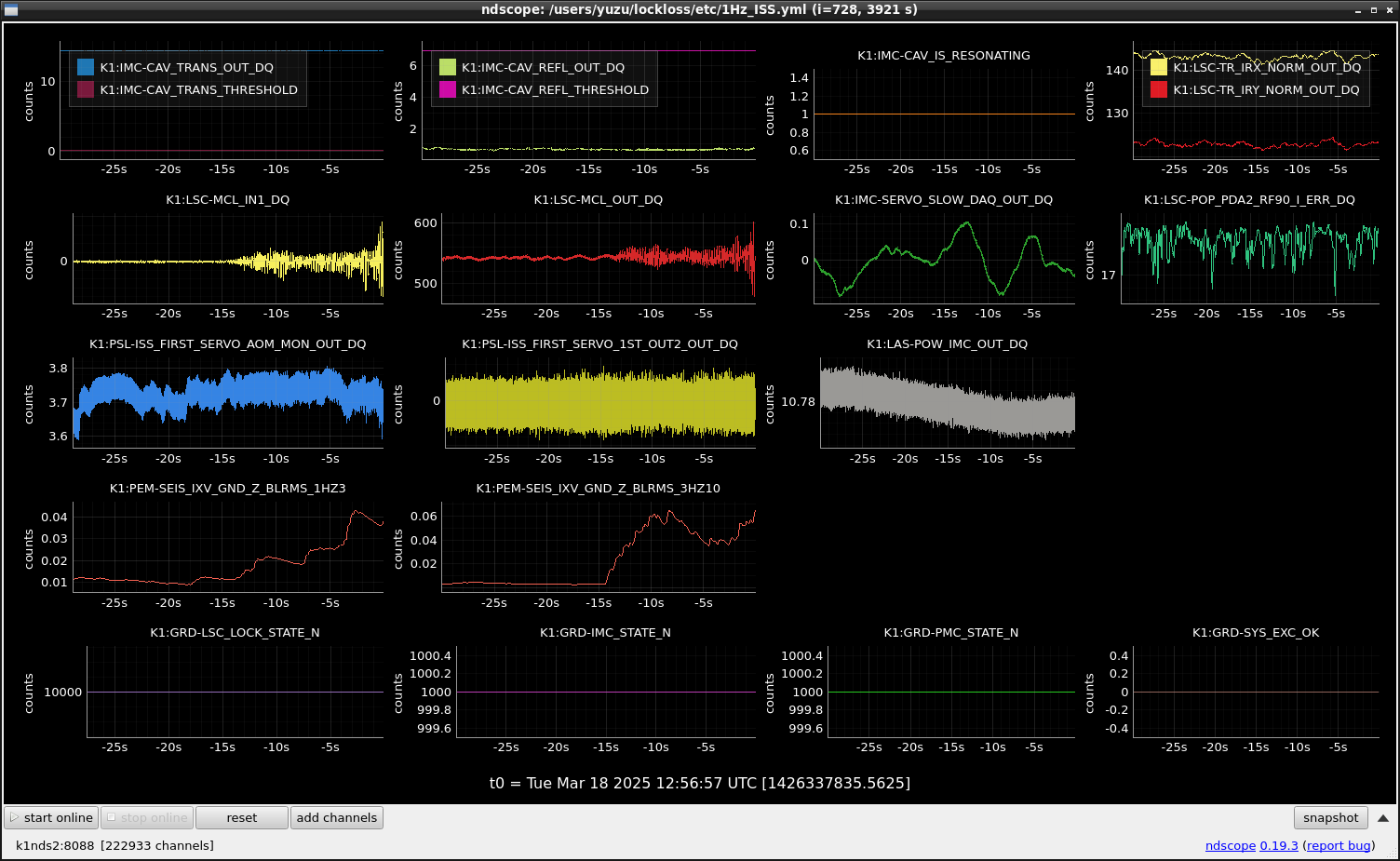
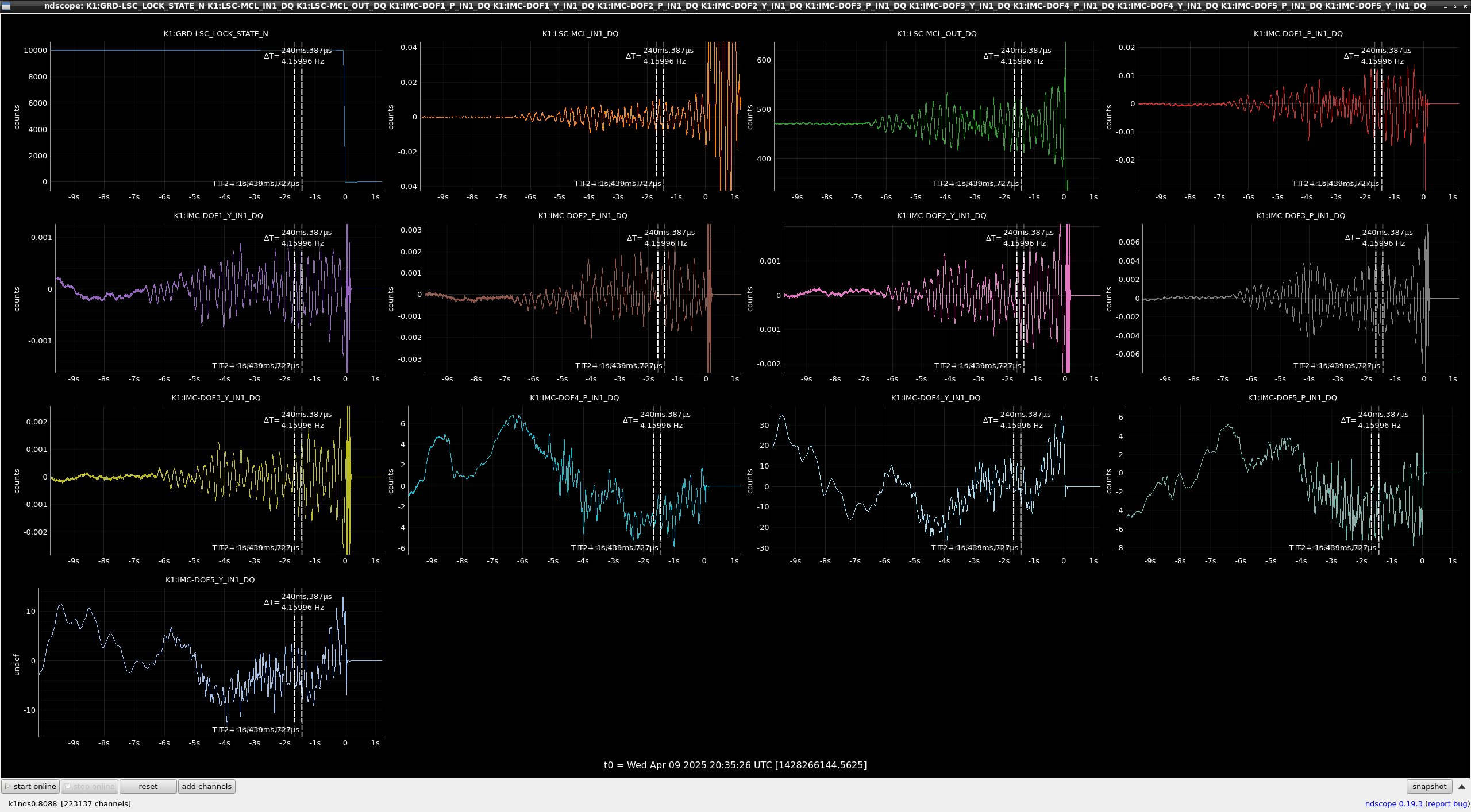
This guardian provides following things (see also the attachment as an example) when a jump to LOCKLOSS in LSC_LOCK guardian is detected.- GPS/UTC/JST times which are aligned with the sampling timing of DAQ (not a guardian log time)
- State name of LSC_LOCK guardian just before jumping to LOCKLOSS.
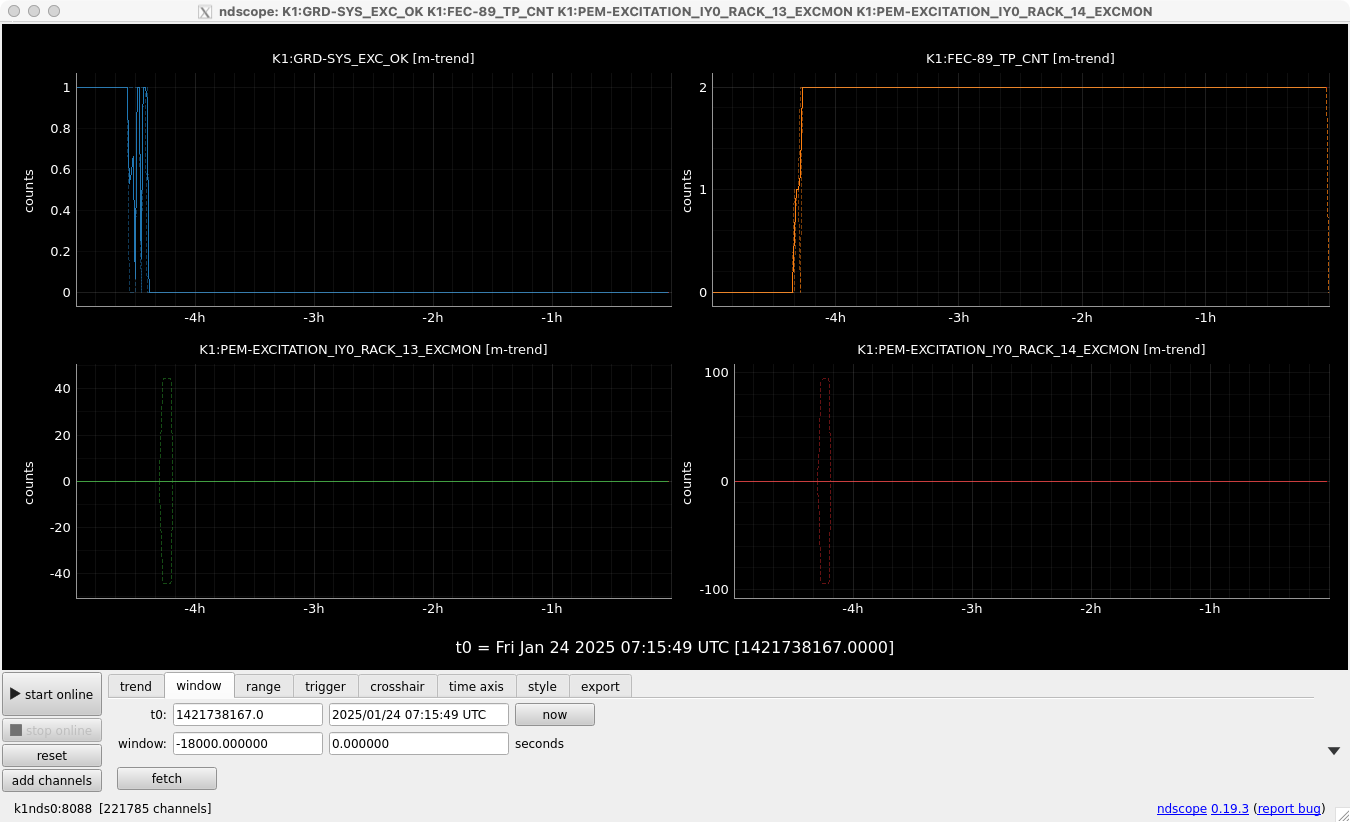
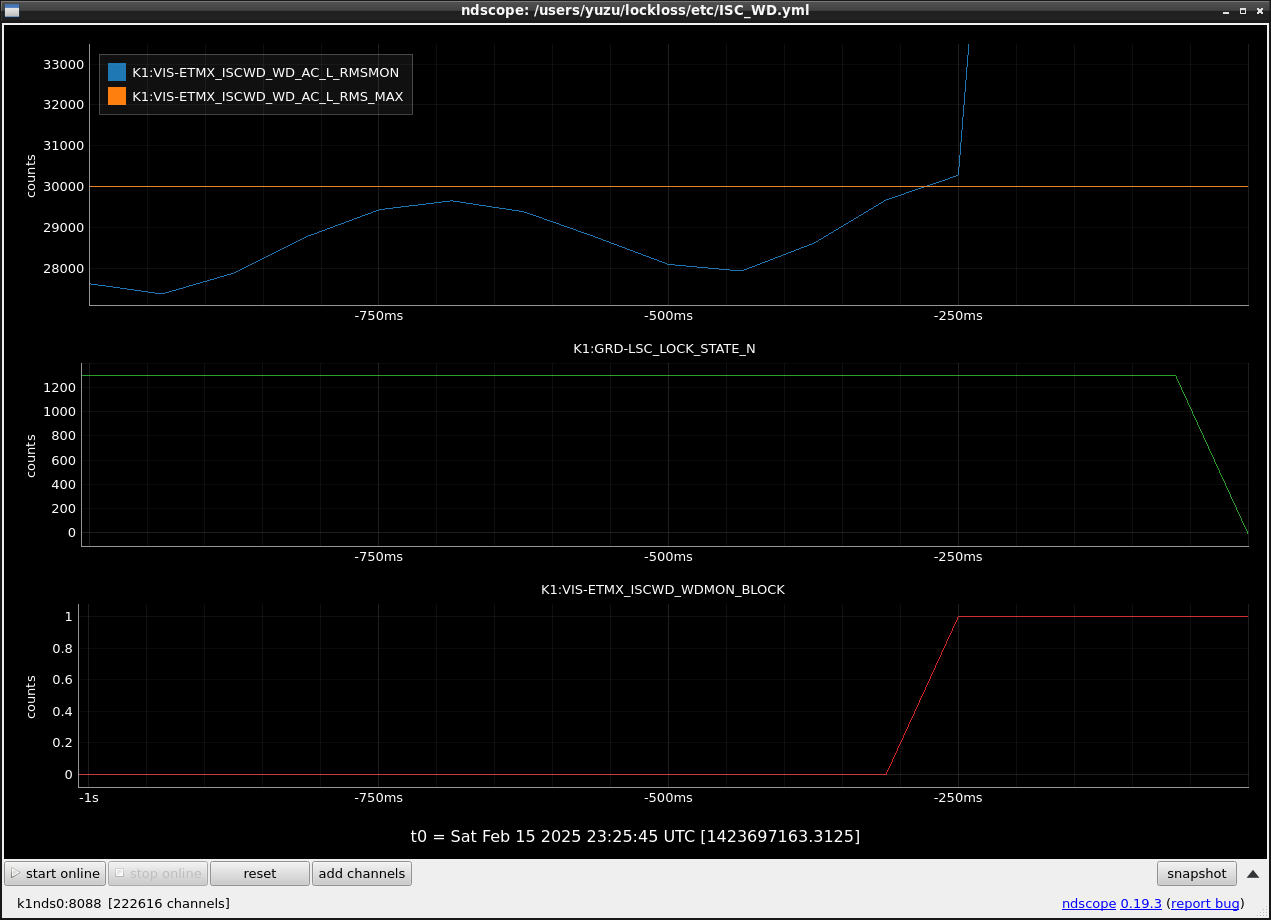
- Guardian nodes which detects lockloss earlier than (or at the same time in the DAQ interval) LSC_LOCK.
- Label of known issues such as klog#31032, and O4a experiences.
It would reduce the effort of checking for lockloss, because it would narrow down the items to be checked by automatically labeling known issues and revealing the behavior of other guardian nodes.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}